Date and Time
Date and/or time are the fundamental data points in many domains like stock price analytics, IoT sensor data analytics etc.. In Python we use datetime module for the most part. If you have followed our eBook on Python, you would have played with the datetime module and time module: https://ebooks.mobibootcamp.com/python/datetime.html
While the Python modules for dates are good for creating one time, individual date object, there are no built in structures for handling large arrays of dates. In Data Analytics we predominantly use collection of dates and rarely use a single date object. That is when NumPy's datetime64 datatype comes to our rescue. datetime64 provides array support for datetime functionality along with supporting many common date formats right off the bat.
Pandas library makes use of NumPy datetime structures; datetime64 and timedelta64 dtypes along with structures in dateutil package and also uses a large number of structures from other Python libraries like scikits.timeseries. Pandas package has also created new functionality for manipulating time series data.
Dateutil package
When you install Pandas or Anaconda, dateutil package is also installed. This package provides a very handy parser which eliminates the need to use the strptime datetime method. Recall the date parsing shown using Python datetime module at https://ebooks.mobibootcamp.com/python/datetime.html
Here is a date parsing example using dateutil which simplifies the task:
from dateutil.parser import parse
print(type(parse('2018-01-31')))
print(parse('Jan 31, 2018 11:45 AM'))
# In many locales around the world,
# day appears before month in a date representation, so pass dayfirst=True
print(parse('1/12/2018', dayfirst=True))
Output:
<class 'datetime.datetime'>
2018-01-31 11:45:00
2018-12-01 00:00:00
As you can see from the above example using the parse function from dateutil simplifies date parsing as many standard date formats are automatically identified and parsed. Pandas uses this parser while reading files into a DataFrame which is explained in the next sections in detail.
Beware of dateutil.parser parsings!
dateutil.parser may parse values erroneously. For e.g., a string value of '65' will be parsed as the year 2065 with today’s calendar date. Watch out if that is not what you intended to do!
Pandas Date/Time
By using all the modules explained above, Pandas has exposed two convenient date/time structures that can be used with Series and DataFrame; the two main building blocks of Pandas.
Timestamp: Pandas has a structure called Timestamp which is essentially a replacement for Python's datetime and is interchangeable with it in most cases. Pandas stores timestamps using NumPy’s datetime64 data type at the nanosecond resolution.
DatetimeIndex: Pandas DatatimeIndex is used to create an index of Timestamp types. This can work as an index for both Series and DataFrame
Note however, that you can set a datetime type object to a DatetimeIndex and automatically they are converted to Timestamp. You really do not have to do anything extra for getting a Timestamp. A series with Timestamp/datetime values as its index will become DatetimeIndex under the hood.
Timeseries
A Series object made out of Timestamp related contiguous data as its index, is a time series. The series could be just dates without time, or with both date and time. Time series data are prevalent in finance/economics (stock prices over time, company turnover on monthly or weekly basis etc.), in biology (how diseases spread over time, multivariate observations of molecules and proteins over time etc.), in Physics (speed/acceleration over time etc..), in Companies (customer's usage data, log data) etc..
There is nothing as simple and elegant as a line chart. A line chart displays information as a series of data points connected by a line segment. Line chart is the de-facto standard for showing time series data.
Weekly Visitor Count

In Pandas you can slice, aggregate and chart the time series data just like any other numerical data that we have worked with so far.
Plotting timeseries data
Once you have the index of Series or DataFrame made up of Timestamp datatype, it is very easy to plot a line graph. Here is an example:
import pandas as pd
detroit_demolitions = pd.read_csv('https://storage.googleapis.com/mbcc/datasets/Detroit_Demolitions_withColumns.csv',
parse_dates=[4])
# for column names, replace space with an underscore and also change the case to lower
detroit_demolitions.columns = detroit_demolitions.columns.str.replace(' ', '_').str.lower()
# strip $ symbol and convert the type to float for 'price' column
detroit_demolitions['price'] = detroit_demolitions['price'].str.lstrip('$').astype(float)
# Get a timeseries to plot
ts = pd.Series(detroit_demolitions['price'].values, index=detroit_demolitions['demolition_date'])
ts.plot()

In the above example, after all the cleaning steps, you create a new Series object with two columns; 'price' and 'demolition_date'. The index of this Series object is set with the values from 'demolition_date' column. Then by invoking the 'plot()' method on the Series object, you get the line graph of prices vs date.
Note, however that you can also plot by directly using the column from the DataFrame. You will see those examples in the stock price plots below.
Now run the below statement and see what is printed out
ts.index
Did you create DatetimeIndex type? No, but your datetime column Series is automatically converted to a DatetimeIndex behind the scenes.
You can also select a particular index by sending the date as a string as shown below
ts['2016-03-08']
Output:

Now you see that there were many demolitions on March 8th. So the index is not unique really as there are many duplicates and that is allowed.
You can in fact give the selection in any standard format and it will parsed to get the correct selection. Try the below statement and you will still see the same result:
ts['03/08/2016']
Output:
You can also input just the year and all the entries for that year will be selected:
ts['2016']
Output: Not shown to keep it concise but encourage you to try on your machine
You can also perform a range query:
ts['1/6/2017':'1/11/2017']
Output: Not shown to keep it concise but encourage you to try on your machine
Now that we see that indexes are having duplicates, we can even groupby on date by passing level=0 (which stands for the one index that we have). In case of MultiIndex scenarios you choose a level other than 0.
ts.groupby(level=0).count()
Output: Not shown to keep it concise but encourage you to try on your machine
In place of count you could also use mean() or sum() and accordingly the 'price' will be summed or averaged accordingly.
Resampling and Frequency Conversion
While the above plot is against all the dates in the dataset, sometimes you may want to find monthly, weekly or yearly aggregation instead of every date entry. You may even want to aggregate based on the date itself. Now that we know that every date has many demolitions, you may want to aggregate the total price for every day and then plot that graph. The process of converting a time series from one frequency to another is called Resampling.
In resampling there are two commonly used scenarios:
- Downsampling: Changing higher frequency data to lower frequency data. E.g., converting daily or weekly frequency data to monthly, quarterly, yearly etc..
- Upsampling: Changing lower frequency data to higher frequency data. E.g., converting monthly frequency data to daily, weekly..
You use the resample method on Pandas to get these conversions. Below is an example to convert the above referenced daily frequency data to monthly frequency:
ts2 = ts.resample('M', closed='right', label='right').sum()
print(ts2)
ax = ts2.plot()
ax.set_yticklabels(pd.Series(ax.get_yticks()).map(lambda x: '{:.0f}'.format(x)))


'M' stands for Monthly, closed represents which side of the bin interval is closed; label represents which bin edge label to label bucket with. Notice that the y_ticklabels are set by changing the numerical data from y_ticks to strings. Otherwise you will see the plot with exponential values.
Official reference
- Resample parameters and their significance: https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.resample.html
- Reference for Interval: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Interval.html
You can also select only 2017 data if you want and aggregate it on monthly basis by running the below statement:
ts2 = ts['2017'].resample('M', closed='right', label='right').sum()
ts2.plot()

Exercise:
- Resample to Quarterly and Yearly with price aggregation and plot the graph
Parsing Date With DataFrames
When it comes to parsing date to a Timestamp from a string value in a dataset, there are a few options:
to_datetime method of DataFrame
In the below example, you will first read the csv file from Google storage and then parse the date column.
import pandas as pd
detroit_demolitions = pd.read_csv('https://storage.googleapis.com/mbcc/datasets/Detroit_Demolitions_withColumns.csv')
print(detroit_demolitions.info())
print(detroit_demolitions.head(1))
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12227 entries, 0 to 12226
Data columns (total 11 columns):
Address 12227 non-null object
:
Demolition Date 12227 non-null object
:
Address |
Parcel ID |
Contractor Name |
Price | Demolition Date |
Commercial Building |
Council_District | Latitude | Longitude | Location | Neighborhood | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 19493 Concord |
15011348. | MCM | $12530.82 | 08/07/2014 |
No | 3 | 42.438562 | -83.033366 | 19493 Concord\n(42.438562, -83.033366) | Nortown |
From the output above you notice that the Demolition Date column is an object type. Using the type command you will see that the value is a String type
type(detroit_demolitions['Demolition Date'][0])
Output:
str
Now you can covert this String to Pandas Timestamp using to_datetime method by specifying the format of the string date. If you see in the above output the date is in the mm/dd/yyyy format and so using the below formatter you can convert string to date type.
detroit_demolitions['Demolition Date'] = pd.to_datetime(detroit_demolitions['Demolition Date'], format='%m/%d/%Y')
As the date string is in one of the standard formats, you can skip giving the format argument in the above example. However it is a good practice to give this argument to ensure that dates are not erroneously parsed when the date string is in a non-standard format.
parse_dates argument
However, there is a more elegant solution to the above problem; You can use parse_dates argument to convert the string to Timestamp while reading the csv file. Below is the shortened code to perform the same task:
detroit_demolitions = pd.read_csv('https://storage.googleapis.com/mbcc/datasets/Detroit_Demolitions_withColumns.csv', parse_dates=[4])
print(detroit_demolitions.info())
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 12227 entries, 0 to 12226
Data columns (total 11 columns):
Address 12227 non-null object
:
Price 12227 non-null object
Demolition Date 12227 non-null datetime64[ns]
:
In the above code you set the argument parse_dates with the column number to apply the default parser. Since the date is the 5th column in our dataset, you see [4] as the column number. Notice that we did not pass any formatter in this implementation. That is because the date string is in the standard format and the default parser will suffice.
However if you have date string in a non-standard format, then you can pass your own parser function to use for date conversion. Here is an example:
parser = lambda mydate: datetime.strptime(mydate, '%m/%d/%Y')
pd.read_csv('https://storage.googleapis.com/mbcc/datasets/Detroit_Demolitions_withColumns.csv', parse_dates=[4], date_parser=parser)
Although the creating a parser for the above example is mute and not required as the default parser is able to do the job for the given string format but in case of non-standard date string, you can create a custom parser as shown above.
Using astype method
You can also use the astype method to convert string values to numpy datetime64 type and an example is shown below:
df = pd.DataFrame({'date':['2018-01-04', '2020-05-03']})
df = df.astype({'date': 'datetime64[ns]'})
df.info()
Official reference
To learn more on constructing your formatter using the format codes refer: https://docs.python.org/3/library/datetime.html#strftime-and-strptime-behavior Using astype:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.astype.html
Moving window functions
Rolling operator resembles resample and groupby and can be called on a Series or DataFrame. You pass the 'window' argument which is expressed as the number of periods which enables grouping over the period passed as argument. In the below example sliding window period is 100. Sliding window is useful for smoothing noisy or gappy data. Of course you can change that 100 to any number of periods over which you want to find the average. The bigger the window the bigger the smoothing effect you see. Smallest window resembles the daily price plot itself.
import pandas as pd
df = pd.read_csv("https://storage.googleapis.com/mbcc/datasets/HistoricalQuotes%20AMZN.csv", parse_dates=True, index_col="date")
df = df.apply(lambda x: x.str.replace(',', ''))
df = df.apply(pd.to_numeric)
df.open.plot()
df.open.rolling(100).mean().plot(title="AMZN closing price and 100 day moving window average")

By default rolling functions require all of the values in the window to be valid. That is why you see that the rolling window plot ends before the daily price plot as there are no values for future 100 days to calculate the last period. To change this you can pass min_periods argument which specifies minimum number of observations for the calculations. Reference : https://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.rolling.html
Below you see an example with min periods set to 10 and here we calculate standard deviation for the window period instead of mean.
import pandas as pd
df = pd.read_csv("https://storage.googleapis.com/mbcc/datasets/HistoricalQuotes%20AMZN.csv", parse_dates=True, index_col="date")
df = df.apply(lambda x: x.str.replace(',', ''))
df = df.apply(pd.to_numeric)
df.open.plot()
df.open.rolling(200, min_periods=10).std().plot(title="AMZN Stock Closing Price and moving window of std")

Annotations in Matplotlib
You can add annotations with text and arrows to high light certain important points in your charts. You can even add just text to show some important message. Both these are applied on the subplot object. Here is an example in which we first get the handle on the subplot ax, and then use annotate and text functions to add annotation and text respectively.
import pandas as pd
df = pd.read_csv("https://storage.googleapis.com/mbcc/datasets/HistoricalQuotes%20AMZN.csv",parse_dates=True, index_col="date")
df = df.apply(lambda x: x.str.replace(',', ''))
df = df.apply(pd.to_numeric)
from datetime import datetime
ax = df.open.plot()
x_point = datetime(2016,11,4)
y_point = df[df.index == x_point].open + 100
ax.annotate('2016 Election Date', xy=(x_point, y_point + 10),
xytext=(x_point, y_point + 225),
arrowprops=dict(facecolor='black', headwidth=4, width=2, headlength=4),
horizontalalignment='right')
ax.text(datetime(2017, 1, 1), 700, 'Post election rally')
#Zoom to certain x and y range by setting the xlim and ylim
ax.set_xlim('1/1/2016', '1/1/2018')
ax.set_ylim(500, 1250)
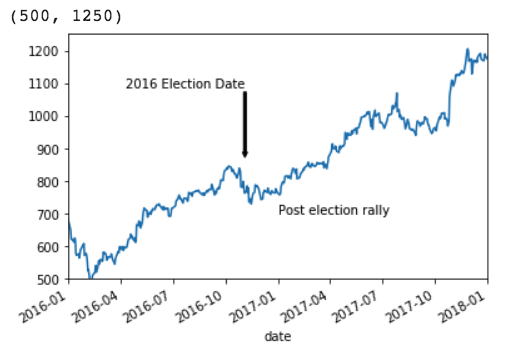
In the annotate method, the xy point is the point of annotation and if the optional xytext is given then the text will be added at the given x and y point. The line length will be computed automatically by taking the distance between the annotation point and annotation text. Setting x_lim and y_lim allows you to zoom in to the specific portion of the chart.
There are many other optional attributes and the full reference is here: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.annotate.html
The text function takes the x value, y value and the value of the text to be displayed. Here also there are other optional attributes you can set.
Reference: https://matplotlib.org/api/_as_gen/matplotlib.pyplot.text.html
Remote Data Into Pandas
You can directly get the data from many different remote sources mostly connected with financial and ticker symbols using Pandas datareader library.
Refer to this link to learn more: https://pydata.github.io/pandas-datareader/remote_data.html