Joining Datasets
There are times when you have to join two or more datasets before you do your analysis. Broadly you can classify the joining as:
- Joining horizontally, resulting in adding additional columns from the two separate datasets but there may not be significant increase in the total number of rows. This is similar to SQL database joins.
- Joining vertically, resulting in adding all the rows and thereby the number of columns may not increase significantly.
Pandas provides operations for both of these techniques. Here are the examples:
merge operation
In this below example we will create two separate dataframes and then merge them on their index.
raw_data1 = {
'fruit_id': ['1', '2', '3'],
'name': ['Apple', 'Banana', 'Orance']}
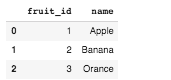
df1 = pd.DataFrame(raw_data, columns=['fruit_id', 'name'])
df1
raw_data2 = {
'fruit_id': ['1', '2', '3', '4'],
'calories': ['55', '50', '45', '60']}
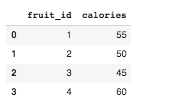
df2 = pd.DataFrame(raw_data2, columns=['fruit_id', 'calories'])
df1
df3 = pd.merge(df1, df2)
df3
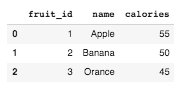
Note column to join on is not specified. If that information is not specified, merge uses the overlapping column names as the keys. Although it is a good practice to specify explicitly and here is the recommended way:
pd.merge(df1, df2, on='fruit_id')
If the 'on' is not specified and if there are more than column which overlap then the merge fails and exits with an empty result.
Also, did you notice something? The second dataframe has an extra row which is missing in the merged result. This is because there is no corresponding row in the df1 and the join method applied is 'inner'.
To change this join you can specify the attribute 'how' and the possible values are 'left', 'right' and 'outer'. The below example uses 'outer'
pd.merge(df1, df2, how="outer")
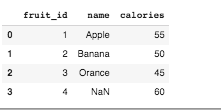
Try the 'left' and 'right' joins and see the results. If you specify 'left' join then all the rows in the left will be kept if there if there is no matching key in the right dataframe and the for the 'right' option the result is the opposite. An outer join keeps both sides by inserting null values for the missing columns
If the column names are different then you can specify that separately:
pd.merge(df1, df2, left_on='df1Id', right_on='df2Id')
where 'df1Id' and 'df2Id' are the join columns for the two dataframes.
Note: If you have duplicate values in columns, then merge will insert rows for all duplicate keys. Here is an example to make it clear:
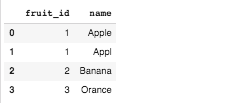
raw_data1 = {
'fruit_id': ['1', '1', '2', '3'],
'name': ['Apple', 'Appl','Banana', 'Orance']}
df1 = pd.DataFrame(raw_data1, columns=['fruit_id', 'name'])
df1
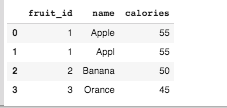
raw_data2 = {
'fruit_id': ['1', '2', '3','4'],
'calories': ['55', '50', '45', '60']}
df2 = pd.DataFrame(raw_data2, columns=['fruit_id', 'calories'])
df3 = pd.merge(df1, df2)
df3
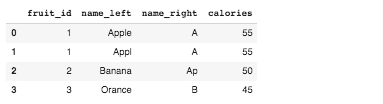
Lastly if the join columns are specified and there are other overlapping column names other than the join column in the two dataframes then pandas automatically appends x and y for the overlapping names. However you can specify the renames to be used as shown below
raw_data1 = {
'fruit_id': ['1', '1', '2', '3'],
'name': ['Apple', 'Appl','Banana', 'Orange']}
df1 = pd.DataFrame(raw_data1, columns=['fruit_id', 'name'])
raw_data2 = {
'fruit_id': ['1', '2', '3','4'],
'name': ['A', 'Ap','B', 'O'],
'calories': ['55', '50', '45', '60']}
df2 = pd.DataFrame(raw_data2, columns=['fruit_id', 'name', 'calories'])
df3 = pd.merge(df1, df2, on="fruit_id", suffixes=('_left', '_right'))
If you want to merge on index and not on column names then you can specify that using left_index=True and/or right_index=True as shown below:
pd.merge(df1, df2, left_index=True, right_index=True)
concat operation
If one set of dataframe rows should be appended with the second, you use the 'concat' operation. Here is an example:
raw_data1 = {
'fruit_id': ['1', '2', '3'],
'name': ['Apple', 'Banana', 'Orange']}
df1 = pd.DataFrame(raw_data1, columns=['fruit_id', 'name'])
raw_data2 = {
'fruit_id': ['4', '5', '6'],
'name': ['Mango', 'Pineapple', 'Kiwi']}
df2 = pd.DataFrame(raw_data2, columns = ['fruit_id', 'name'])
df3 = pd.concat([df1, df2])

Do you notice that the indexes are duplicate? To ensure that the indexes are not considered in concatenation, use 'ignore_index=True' attribute
pd.concat([df1, df2], ignore_index=True)
With this you will have a new index formed which is of contiguous value.
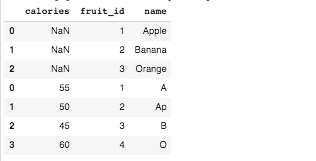
If however, the columns are not aligned for appending then extra columns are added from the concatenated dataframe and NaN values are inserted for missing values. Here is an example:
raw_data1 = {
'fruit_id': ['1', '2', '3'],
'name': ['Apple', 'Banana', 'Orange']}
df1 = pd.DataFrame(raw_data1, columns=['fruit_id', 'name'])
raw_data2 = {
'fruit_id': ['1', '2', '3','4'],
'name': ['A', 'Ap','B', 'O'],
'calories': ['55', '50', '45', '60']}
df2 = pd.DataFrame(raw_data2, columns=['fruit_id', 'name', 'calories'])
df3 = pd.concat([df1, df2])
Using append
Instead of using concat of pd you can also use append on DataFrame to join multiple DataFrames. Here is an example;
import pandas as pd
d1 = {'col1': [1, 2], 'col2': [3, 4]}
df1 = pd.DataFrame(data=d)
d2 = {'col1': [5, 6], 'col2': [7, 8]}
df2 = pd.DataFrame(data=d)
df3 = df1.append(df2)
df3
Output:
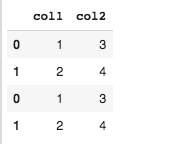
Notice that the index numbers of individual DataFrames are retained in the appended DataFrame. To form a new index, use ignore_index=True attribute as shown below;
df3 = df1.append(df2, ignore_index=True)
Output:
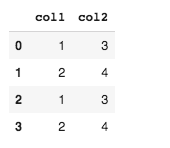
You can use either concat or append although concat provides more options.
Comparing Dataframes
When you want to compare two dataframes, use the equals method as shown below instead of using == operator. This is because with == operator, one NaN is not considered equal to another NaN. And for values which are NaN's the == with return False. Also note that DataFrame index needs to be in the same order for equality to work correctly.
df1.equals(df2)