Data Cleaning
Garbage In Garbage Out
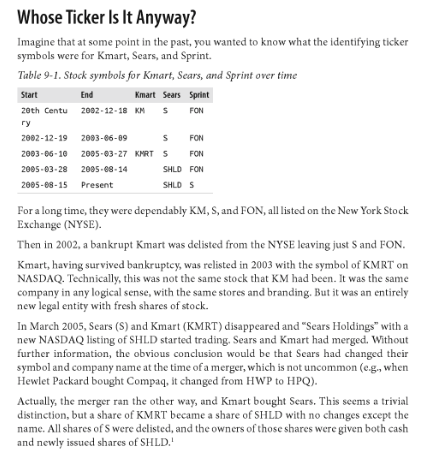
Any good analysis depends on the solid foundation of good data. However in most real world Data Analytics scenarios starting with a clean data is a distant dream! In majority of the cases, most of the time is spent cleaning the extracted data. Because if you base your analysis on a bad data your analysis is also bad!
Typical issues:
- Missing fields - This is the most common issue in a dataset. Some fields in a tabular data are missing.
- Differently formatted data in the same column. E.g, date column having mmddyyyy and any other variation of date format in the same column
- Data just does not make sense - A person's age column having -10 as the value. Values not in expected set (list of 50 states does not have AA for e.g., ) etc..
What is Data Wrangling?
Process of cleaning (including removing bad data, fixing missing data, fixing format issues etc.) and unifying messy and complex data sets for easy access and analysis.
End goal of the data wrangling step is to ensure data scientists can focus on data analysis with ease. Data Wrangling in many complex cases will be an iterative process as all the mess will not be visible in one go.
Common Causes of Erroneous Data
- Human data entry errors - after all humans! Typos, missed entries, entries in wrong fields etc..
- Program errors: e.g., OCI errors (Optical character recognition). An OCI may incorrectly identify characters.
- Data from different data databases and with different schemas merged together without proper matching of columns.
- Evolving applications. In many applications, the business starts with an initial set of columns for data collection and subsequently realize they need more columns to hold newly discovered data. But by the time they discover, they would have already collected sufficient data. When the new column is introduced, the old records may have empty values for the new column.
- Errors while converting data from one format to another etc.
- Data corruption during transmission from one storage to another.
- Numerical values that are 99.99 signify empty/null values in some legacy computer systems. Beware of these mixed up with valid values.
Steps for Data Cleaning
- Compile a Valid set of values for each field - manually audit for some values. Ask relevant questions while compiling your list. Eg., Start date must come before end date, age column having negative values etc..
- Audit the data programmatically and compile the outliers and oddities. Investigate the outliers to determine if it is erroneously entered or truly an interesting phenomenon worth noting. E.g., age being 130 in a column where the average age is 28. Is this a typo or truly a valid outlier?
- Make data consistent. E.g., If you have two different ways of representing country codes; US in some places and USA in some places then, either have two digit codes for all countries or change all countries to three digit code based on the data and what makes sense.
- Remove duplicate rows if present.
- Address consistency issues. E.g., A user has three types of location information; Address entered by user, GPS Location from user Device, and Network Provider from user's device ..All are different; Which is accurate?
- Rename columns if the original names are unwieldy. This step will save you lot of pain while writing queries.
- Once all flaws are detected, develop plan for cleaning and write code to clean.
- Choose between first cleaning and then loading or clean after load one record at a time based on your requirements and performance criteria.
- It is an Continuous Iterative process. Your iterative process could be a mix of automated programs and manual intervention for both correcting the data and verifying the data, till you have cleaner data in every iteration and you are confident of your data.
Although each dataset is different and hence the problems you encounter are different and it would be rather exhaustive to list out all possible dirty data scenarios. Domain knowledge is also essential to truly understand your data.
Case Study of Bad Data borrowed from Bad Data Handbook given below
Handling missing values
When certain fields have missing values, you have a few choices to fix them. Before we understand the techniques for fixing them, let us understand the common scenarios for missing values:
- Missing Completely At Random (MCAR): This type of fields have missing values completely at random and there is no specific reason for them being missing. Since the distribution of this data is as random as the random sample that is used to study the data set, you can safely drop these values if the remaining values are good enough for your analysis. Rule of thumb is you can remove upto 5% of observations due to missing values.
- Missing at Random (MAR): This type of missing field is because of conditional value in another field. In this case there is a systematic relationship between the tendency of certain value missing to another observed data. For example, if Managers are more likely to skip telling their salary compared to union workers in a factory survey, then salary is an MAR. In this case again you can drop the records containing the missing values as there is no specific reason for the values being missing within that category.
- Missing Not at Random (MNAR): In this case the reason for missing is not random and there is a specific reason for why the data is missing. For e.g., people with lowest education are missing entries on education field in a survey. People with very high salaries compared to their peers are missing their salary information etc.. In these cases missing value cannot be ignored. The correct approach would be to do some investigation and impute a correct value.
To classify any missing value into one of the above 3 types , it needs careful study of the data. Once you are fairly confident of the missing value pattern then you can apply of the techniques which make more sense to your specific data.
Some Techniques for Imputing Missing Values
While dropping missing values in case of MCAR and MAR is certainly an option when you have large enough data after dropping the values, there are certain other techniques you can consider if you decide to use imputation instead.
Dropping missing values might not be an option because
- The other fields of a missing value might be very valuable for your EDA and/or ML models
- Many EDA libraries and ML models cannot handle missing values and some algorithms impute the values using some decision logic which may not be the correct way.
Hence analyst has to spend time in understanding the technique to use to impute the missing values and here are some common imputing methods and its usages:
- Mean/median: Impute the value with mean or median. If there are no extreme outliers then imputing with the mean is a good option. If your data is having extreme outliers then imputing with a median is a better option.
- Regression: A regression model is used to predict the missing value based on other variables and finding the impute value from the regression chart.
- Stochastic regression: While the Regression technique produces estimates that fits perfectly on the regression line without any variance, Stochastic regression adds an average regression variance to the predicted value from a regression, there by accounting for error.
- KNN - K-nearest-neighbor: Impute with those values that are nearest to the missing attribute values. The similarity between two attribute values is determined using the distance function
- Last Observation Carried Forward (LOCF): In this technique you first sort data according to any of a number of variables and then find the first missing value and use the cell value immediately before this missing cell to impute the missing value. This process is repeated for the next cell with a missing value until all missing values have been imputed. This method is known to increase risk of increasing bias and hence not very popular. Refer: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3130338/
- Hot Deck : Hot deck imputation is a method for handling missing data in which each missing value is replaced with a value from a 'similar' unit.
- Multiple Imputations: In order to deal with the problem of increased noise due to imputation, Rubin (1987) developed a method for averaging the outcomes across multiple imputed data sets as a remedy. Refer: https://stats.idre.ucla.edu/wp-content/uploads/2016/02/multipleimputation.pdf
Although imputation is a simple concept, it does not really substitute for the real values and hence introduces bias in most cases. So it’s not ideal but might suffice in certain situations.
Quiz:
Here is the GDP (Gross Domestic Product) values of US from 1990 to 2006. For 2002 and 2003, years there is an NaN value for GDP. Which technique will you employ for imputing values for these two years?
