Data Collection Basics
As such a Data Analyst job revolves around Hypothesis and Data. Either s(he) has already been given a hypothesis and is asked to analyze the data to prove or disprove the given hypothesis or the analyst will be asked to formulate a hypothesis and/or produce descriptive summaries that supports the hypothesis.
So..
What is a Hypothesis?
Hypothesis is nothing but a theory or proposed explanation for a phenomenon made on the basis of limited evidence as a starting point for further investigation. Formulating a hypothesis is the stepping stone for grand factual conclusions.
It also means that a hypothesis may also be proved wrong in the end when it is tested against bigger and better data. Nevertheless as a Data Analyst you always try to find a theory or hypothesis hidden in the data. If there is no data available but you only have a hypothesis, then you first collect the data to support your hypothesis. In this chapter you will learn the techniques and terminologies that are used in scientific data collection.
When you need to collect data to support your hypothesis, you first have to figure out how to measure the outcome that corroborates your theory. Let us take an example to make it clear. Hypothetically let us assume there is a company ZingM, which produces a pill to improve human brain memory. ZingM tasked a new researcher to collect data which corroborates the Hypothesis of the company. The first question that comes to anyone's mind is how to measure memory? That brings us to the term construct.
What is a construct?
A construct is a concept that is difficult to measure because it can be defined and measured in many different ways. E.g.; Area; We know Area is a space but Area can be measured in multiple units; sq ft, sq mts etc. likewise; intelligence, happiness, sadness, memory are concepts that by default do not have units of measurement and are called constructs.
In our simple example memory is a construct. To establish the claim that the pill from ZingM improves memory, the researcher need to have a way of measuring memory of people before taking the pill and again measure memory after taking the pill. So the next set of questions that arise is how long should a person take before (s)he can see the effect? Although the answer to this question might be another study by itself, for our current study let us assume that the pill starts taking effect if taken everyday for at least 10 days.
But how to measure memory? While there are many different types of memory and various different ways of measuring them, we will keep things simple by assuming that this pill improves the recall memory.
To measure recall memory, the researcher devices a test in which s(he) shows a set of hard-to-remember medical terms along with their meanings to a group of participants for 10 minutes. After giving a 10 minute break, a quiz is given in which the participant should write down the meaning when a word is shown.
Here is one such list that was handed over to the participants;
- Crepitus - grating, crackling or popping sounds of joints
- Gustatory Rhinitis - runny nose when you eat spicy food
- Horripilation - Goose bumps caused due to cold, fear, or excitement.
- Obdormition - numbness in a limb, often caused by constant pressure on nerves or lack of movement.
- Sphenopalatine ganglioneuralgia - brief headache caused by eating ice cream.
- Fasciculation - Muscle twitch
- Diaphragmatic flutter - hiccups
- Sternutate - Sneeze
- Vasovagal syncope - Fainting on seeing blood or shocking news.
Recall rate; which is basically the number of words for which the participate wrote the correct meaning is scored and then the participants are prescribed the new ZingM pill for 10 days. Researcher, repeats the test after 10 days and measures the improvement in their recall by administering the same quiz.
In the above example the construct was operationally defined so that it can be measured.
What is a Operational Definition?
The operational definition of a construct is the unit of measurement you use for the construct. Once you operationally define something it is no longer a construct. If we define area in sft, then this would be operationally defined. E.g.; Minutes is already operationally defined; there is no ambiguity in what we are measuring.
However sometimes operational definition for a construct is not straight forward. In such cases you measure the expressed or implied actions or behaviors pertaining to the construct. Here are few examples of operational definitions:
- Hunger; measuring a person's hunger can be expressed in terms of how many calories a person can consume before feeling full.
- FastFood sales; It is not easy to find the total number of people eating at a specific fast food restaurant (any restaurant for that matter) as the data is private. However, the total ratings count that the restaurants have received (by extracting the data from websites like Yelp etc.) can work as an operational definition for sales. This technique can be applied to any product, book, movie etc., by collecting the ratings data from websites like Amazon, NetFlix etc.. Some of these companies also provide a RESTful API to help you search their website and get results.
Which of the following are Constructs?
- Intelligence
- Effort
- Gallons of milk
- Hunger
- Annual salary in $
If you identified Intelligence, Effort and Hunger then you got it right! How do you operationally define these? One possible way would be:
Efforts - e.g., Amount of time spent on a task Intelligence - e.g., IQ Test score Hunger - e.g., Grams or calories of food eaten
Researcher conducts the memory test for 10 participants for 10 days and tabulates the score and plots a diagram as shown below:
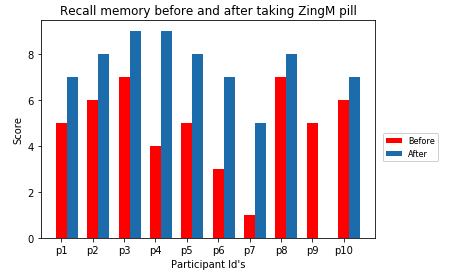
In the diagram, the participant id's are shown on the x-axis and the score is shown on the y-axis.
From the diagram you notice that the score improved for all participants except for one. Only one person had a drop in score from 5 to 0 after taking the pill. If we ignore this one anomaly (a.k.a outlier) you see that taking ZingM pill does have a positive covariance with Memory.
Should the Outliers be Ignored?
The answer is 'it depends'. It is always a good practice to understand the outlier phenomenon before discarding it. Sometimes you are indeed hunting for an outlier in the data. Here are some examples of outliers which are hunted out from the normal data and that itself is a full time job!
- Fraud detection in credit cards, insurance companies - While the normal credit card transactions follow a specific pattern, a fraudulent activity of a stolen credit card transaction looks different (different place, amount or type of purchase) and that is what you are tasked to hunt for!
- Fault detection - Heat and Fire sensors trigger an alarm when there is anomaly in its readings.
- Intrusion detection - Detect malicious activities on a computer or networks based on differences in the regular pattern of behaviour.
However in this hypothetical company, the researcher found that the test score of 0 for this one person was because the subject did not take the test after 10 days as he dropped out of the program. So in this case it is a good idea to drop that record.
Establishing Correlation
ZingM also says that when a participant takes the pill without skipping then you will see a gradual improvement in memory and will attain your full memory capacity by 3 months. The experimenter continues the experimentation and plots the results every 10 days for 3 months. And here is the final plot of results for the final 5 participants as another 4 participants dropped out before the end of 90 days.
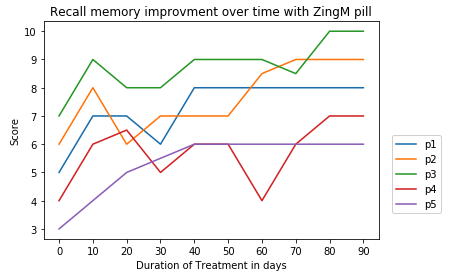
Notice that the treatment duration which is the independent variable is shown on the x-axis and the test score which is the dependent variable is on the y-axis.
When we operationalize a construct, we create Variables! So any characteristic that varies is a variable. At least it should have two values to be classified as a variable. Variables hold data and data comes in various types. In the subsequent chapter Types of Data, you will learn more on variables and data types.
With the above plot the researcher concludes there is a strong positive covariance between treatment duration and higher memory score. He concludes that the positive correlation can prove the hypothesis that ZingM pill causes memory improvement.
Is the conclusion correct?
Not really and here are the reasons:
- There is no mention of the age of the participants.
- There is no mention of how these participants were selected. A group of medical students have a strong advantage on the test as they may already be familiar with the terminologies.
- Just 5 participants is not a big enough number to conclude a causal effect.
- There is no mention of the control group
- There is no mention of if the same set of medical terms were repeated for all the tests.
Any of the above factors and more which were not thought through by the researcher may spring a surprise in the results and show a strong relation between variables when there is none and vice-versa and cause a Simpson's Paradox. These factors are called confounding factors or lurking variables.
For the results to be valid, the experimenter must not only think through the above factors but also ensure the following;
- Obtain a random set of participants for the treatment group.
- Should also create a randomized control group.
- Any other control variable like the food given to the participants, work, stress etc., should be kept constant during the study period.
While lurking variables or confounding factors are unknown to the researcher, control variables are very well known to the researcher. Control variables should be kept constant so that only two variables are in play for the duration of the experiment instead of multiple variables inter playing with each other.
Points to Note
- The Operational definition may not accurately measure a construct
- Confounding factors are variables that never crossed researcher's mind and can distort the results which the researcher is unaware of.
- To prove any Hypothesis, sophisticated models from Inferential Statistics are applied.
- When you find a strong correlation between variables it does not necessarily mean causation. It is easy to find correlationt but much harder to find causation.