YARN - Yet Another Resource Negotiator
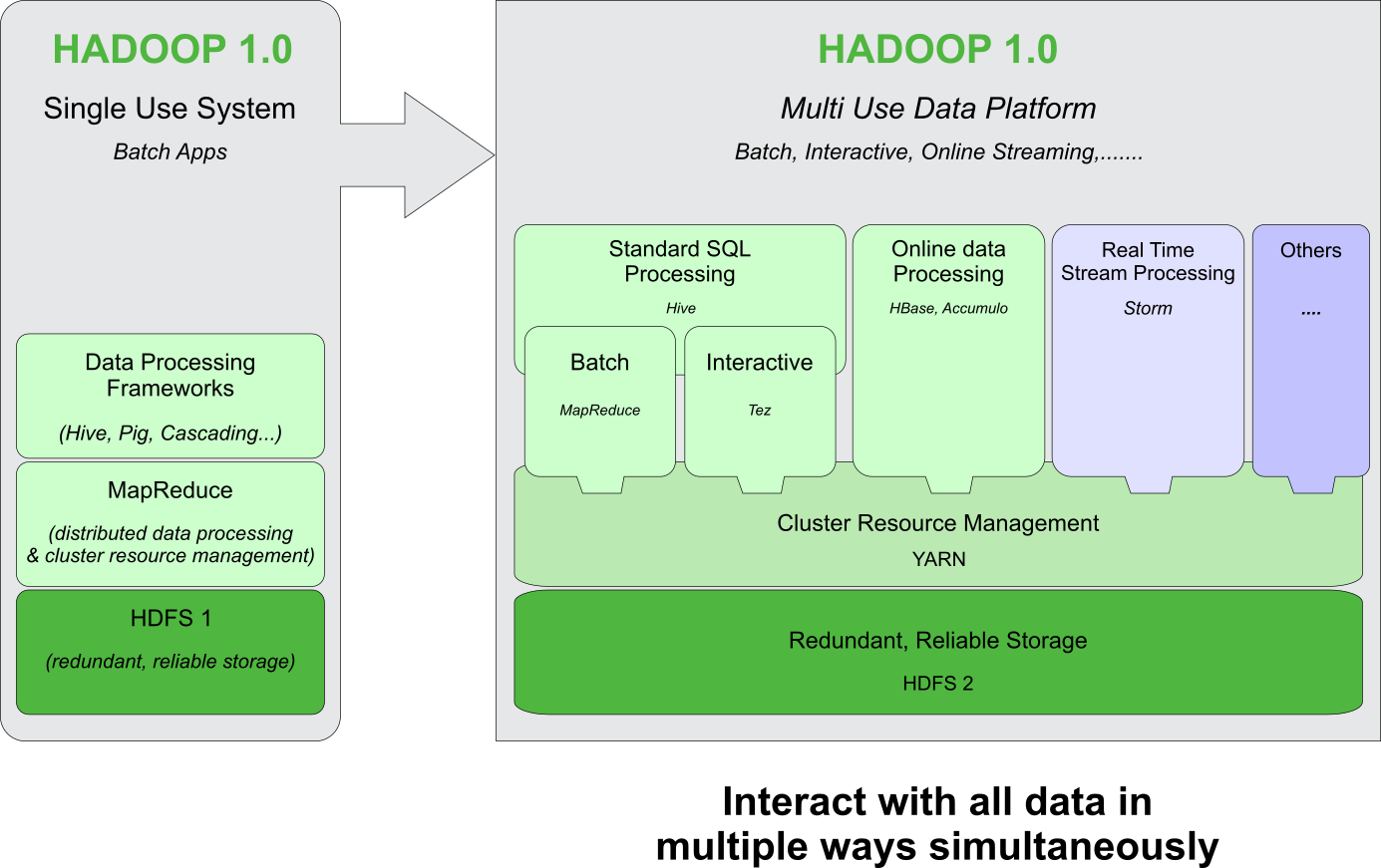
Early Hadoop 1.0 was only capable of handling Map Reduce batch jobs. But the next generation of Hadoop (2.0) came with YARN, that can provide capabilities to not only handle Map Reduce batch jobs but also other generic processing techniques to process real time streaming data along with managing many other applications that make up the Hadoop ecosystem.
If you think about HDFS as the cluster file system for Hadoop, YARN would be the cluster operating system. It is the architectural center of Hadoop.
A computer operating system, such as Windows or Linux, manages access to resources, such as CPU, memory, and disk, for installed applications. In similar fashion, YARN provides a managed framework that allows for multiple types of applications – batch, interactive, online, streaming, and so on – to execute on data across your entire cluster. Just like a computer operating system manages both resource allocation (which application gets access to CPU, memory, and disk now, and which one has to wait if contention exists) and security (does the current user have permission to perform the requested action), YARN manages resource allocation for the various types of data processing workloads, prioritizes and schedules jobs, and enables authentication and multi-tenancy.
YARN is the prerequisite for Enterprise Hadoop, providing resource management and a central platform to deliver consistent operations, security, and data governance tools across Hadoop clusters.
Today, YARN is a resource management framework that is integrated with Hadoop, Spark, Storm, HBase etc.. YARN enables multiple workloads to execute simultaneously in the cluster. YARN makes it easy to build a data lake and allow mixed workloads in the same Hadoop cluster.
What is Data Lake?
Major YARN Components
In Hadoop-1 the JobTracker was responsible for resource management, job scheduling and monitoring. And TaskTracker was responsible for the job itself.
Hadoop-2 uses YARN, which has three main components;
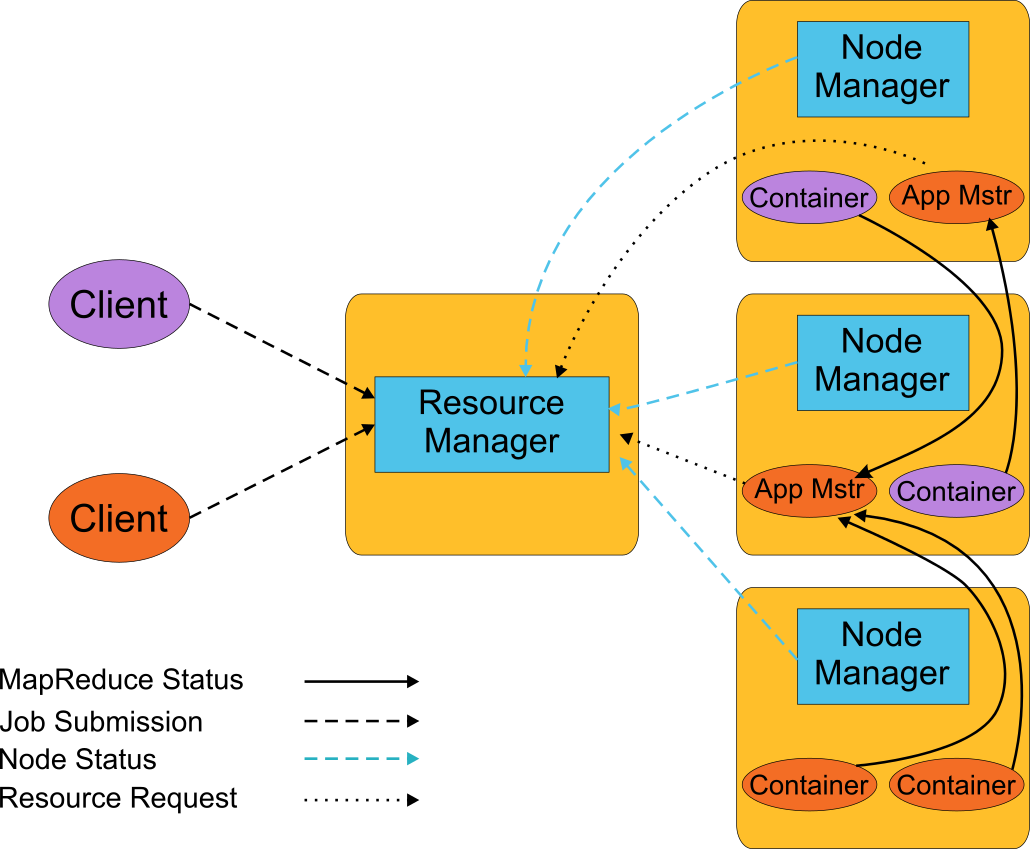
- Resource Manager - one per cluster to manage resources. Master process responsible for fulfilling resource requests
- Node Manager - per-machine process, does the work of Task Tracker. Resides on the worker nodes along with the actual Containers that fulfill job functions. Reports resource usage to ResourceManager
- Application Master - per-application process for application management. Negotiates with ResourceManager for needed resources. Works with NodeManager to execute and monitor application tasks. Resides within a Container and is the process responsible for running a job (batch or long-lived service)
How does YARN spawn processes?
ResourceManager service is spawned on the master node of the cluster. When a client submits a job it reaches the ResourceManager. The job can be a single MapReduce job or a directed acyclic graph of MapReduce jobs, Java application, or even a shell script. The job application defines an ApplicationMaster program.
ResourceManager validates and accepts the job and then allocates a container for ApplicationMaster on a node and the NodeManager starts the ApplicationMaster container.
The ApplicationMaster then requests for resources (memory, cpu cores) from the ResourceManager. The ResourceManager allocates the necessary resources as containers on a set of nodes. ApplicationMaster with request the NodeManagers to start the containers. While the NodeManager is responsible for providing resources and running applications containers, ApplicationMaster manages the progress and execution of the containers.
ResourceManager keeps track of all the available resources across all the Nodes and uses this information to allocate new containers to ApplicationMasters.
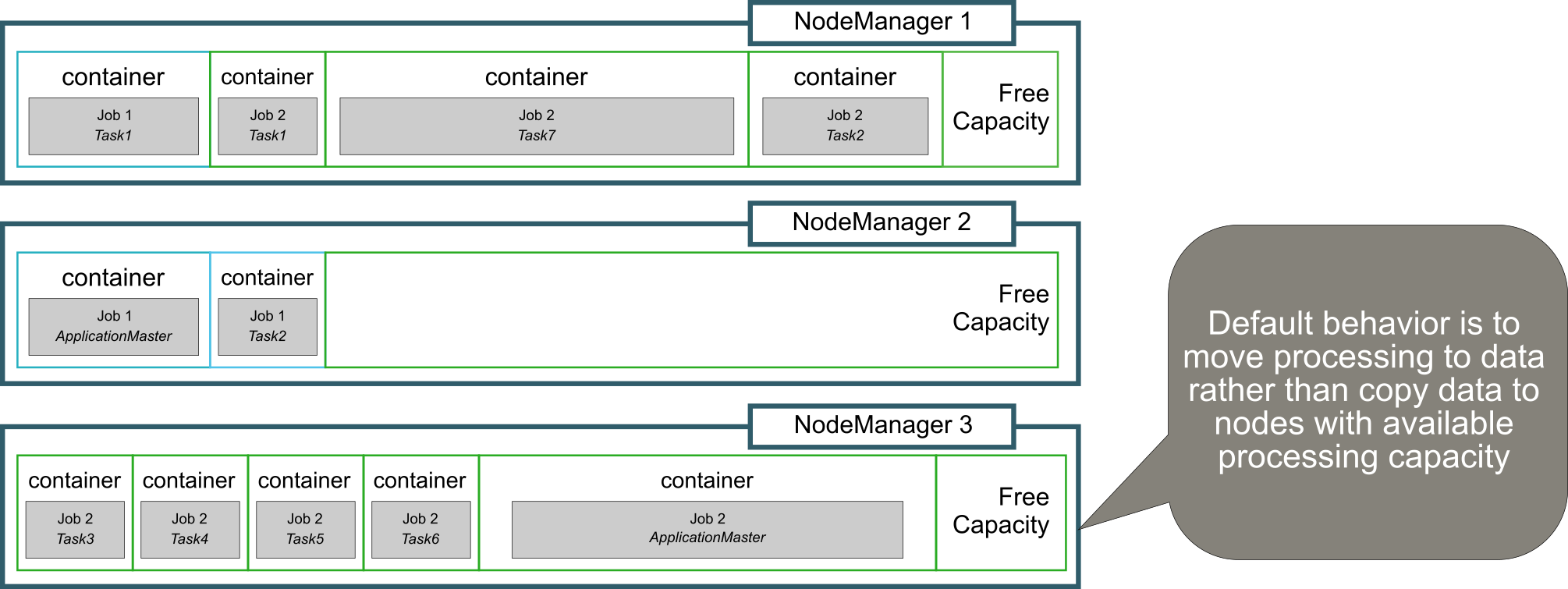
ApplicationMaster can initiate the creation of containers on any appropriate NodeManager in the cluster. The default behavior is for all jobs to be collocated where data blocks already exist, even if more processing power is available on a node without those data blocks whenever possible
YARN spawns
- A global ResourceManager
- A per-application ApplicationMaster
- A per-node slave NodeManager
- A per-application Container running on a NodeManager
Hadoop 3.x.x improvements
Timeline server
In the earlier version the job history server was providing the details of current and past map/reduce jobs executed on YARN. However, other applications which do not use Map/Reduce were not captured. In 3.x.x version, a new YARN timeline server was added which provides information on all applications This captures application information, type of framework used (spark, tez etc..) and logs each step in the application lifecycle and also provides a web interface.
Opportunistic containers:
A new execution type called Opportunistic containers was introduced, These are containers that are scheduled even if there are no resources available at the moment and hence get queued waiting for resources to be available for it to start. Opportunistic containers have a lower priority than the default Guaranteed containers and are therefore preempted, if needed, to make room for Guaranteed containers. This helps improve cluster utilization. Applications can be configured to use both Opportunistic and Guaranteed containers.
Reference: https://hadoop.apache.org/docs/current/hadoop-yarn/hadoop-yarn-site/YARN.html