RDD - Resilient Distributed Dataset.
Spark is build around the concept of an RDD.
Resilient Distributed Dataset (RDD) is an immutable collection of objects (or records) that can be operated on in parallel.
Resilient - data can be recreated on the fly in the event of a machine failure. Can be recreated from parent RDDs – and RDD keeps its lineage information.
Distributed because - operations can happen in parallel on multiple machines working on blocks of data allowing Spark to scale very easily as data and machine network size grows.
Dataset - A set of data that can be accessed.
Each RDD is composed of one, or more, partitions. The user can control the number of partitions, by increasing partitions, the user increase the parallelism.
RDD’s are not persistent objects by default. They are a set of instructions on how to transform data. The only time an RDD ever physically exists is when the data is cached into memory.
For HDFS files, the RDD partitions will be aligned with the file’s blocks thus leveraging the same kind of parallelism that Hadoop is famous for.
Reference: https://www2.eecs.berkeley.edu/Pubs/TechRpts/2011/EECS-2011-82.pdf
Working with RDD
RDDs have the following two types of operations:
- Transformations - The RDD is transformed into a new RDD.
- Actions - An action is performed on the RDD and the result is returned to the application or saved somewhere.
Spark rdd functions are transformations and actions both. Transformation is function that changes rdd data and Action is a function that doesn't change the data but gives an output.
For example : map, filter, union etc are all transformation as they help in changing the existing data. reduce, collect, count are all action as they give output and not change data. for more info visit Spark and Jacek
Transformations are lazy: they do not compute until an action is performed. This is an important concept of Spark. Spark likes to do the least amount of work possible and will only process data when it is forced too.
RDD Persist Options
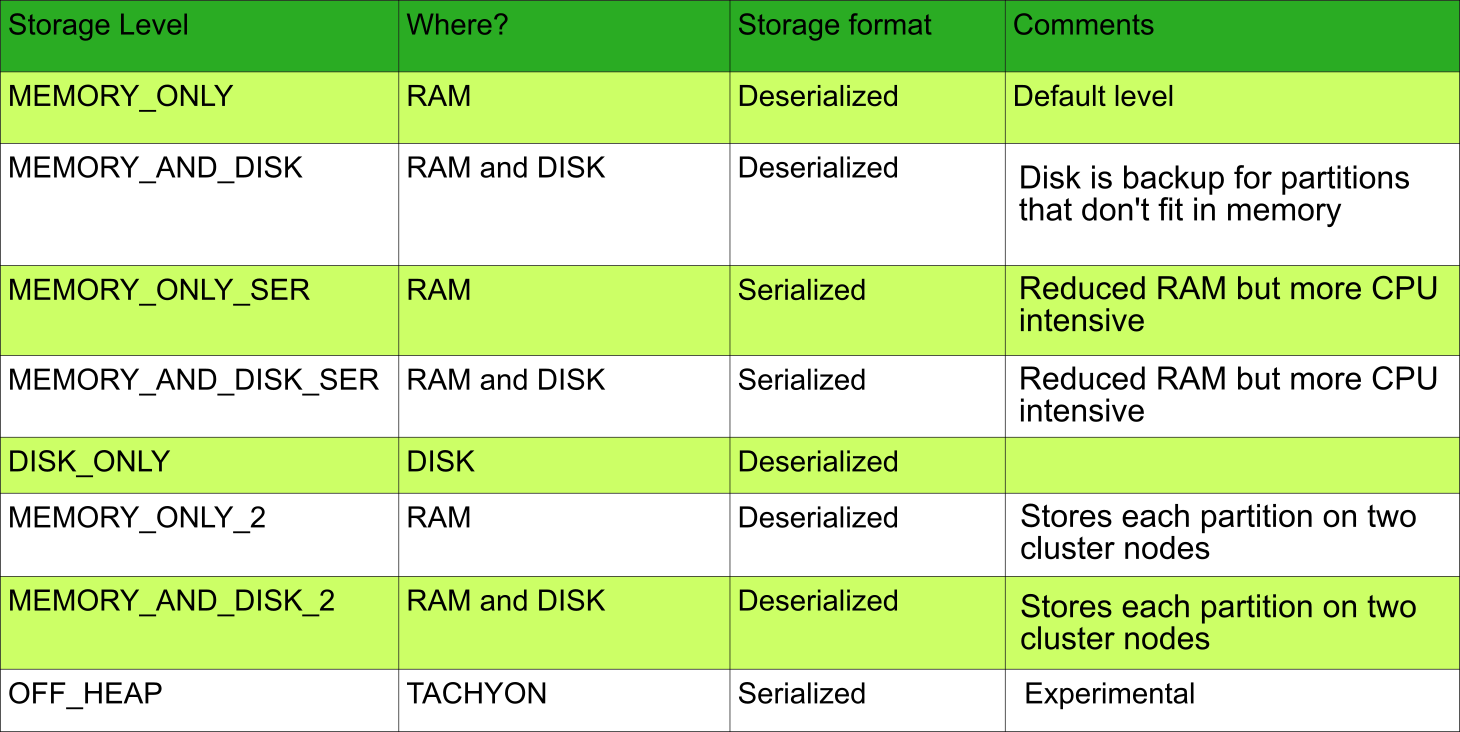
Although by default RDD is stored in-memory. However, if your data is too large to fit into your RAM, then accordingly you can change the settings to also use the disk only if necessary. Although note that the very purpose of Spark is defeated if you use the disk option as disk I/O are slow
RDD Lab
Number count problem
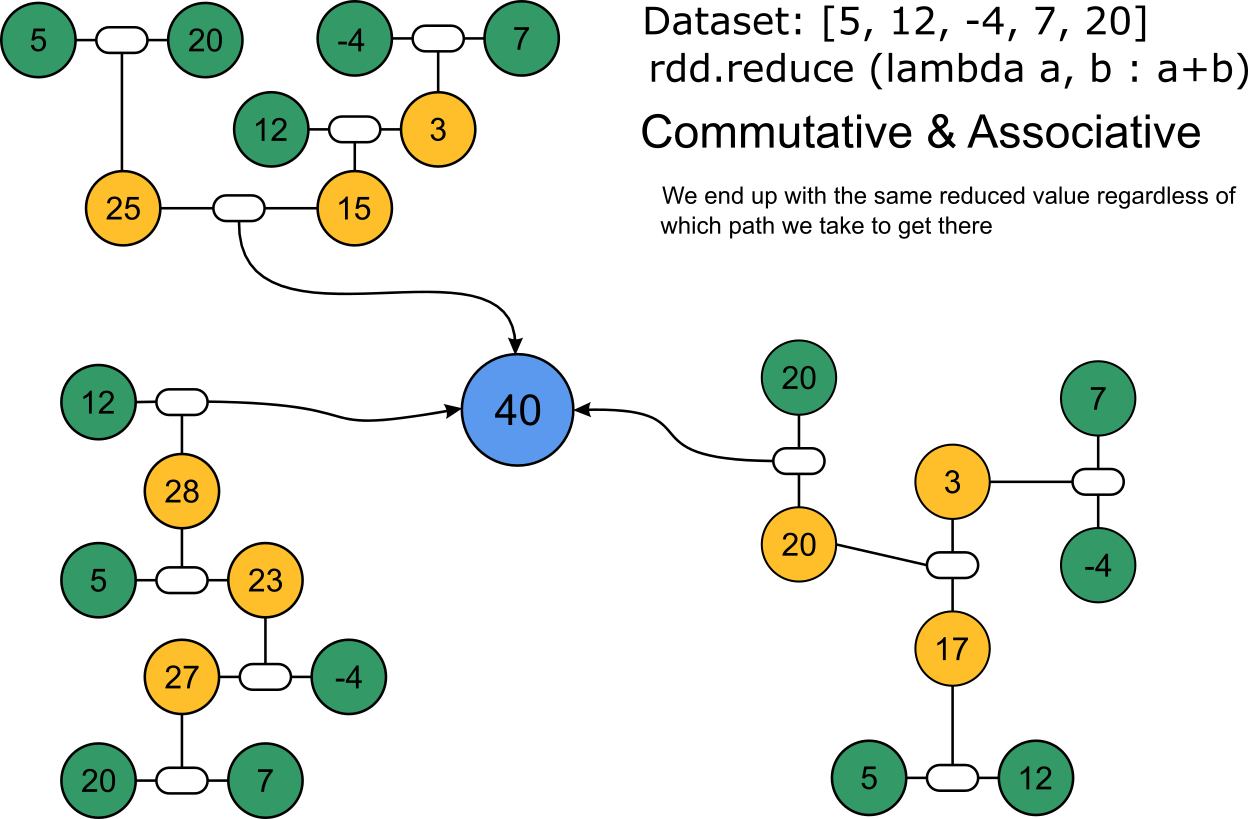
data = [5,12,-4,7,20]
distData = sc.parallelize(data) # create an RDD from local data
distData.reduce(lambda a, b: a+b) # perform reduce action on RDD
# Should output a result of 40
distData.count()
# Should output a result of 5
reduce()
The reduce() action aggregates elements of an RDD using a defined function. The reducing logically happens over and over with only two of the RDD elements at a time. Once those two have been reduced, then the result will be part of another logical reduce step until all elements have been accounted for. This concept of having multiple passes on the reduce phase is similar to the Java MapReduce API's Combiner. The function used by the reduce should be both commutative and associative. For example, a+b = b+a. And a+(b+c) = (a+b)+c.
Other useful spark actions
- first() returns the first element in the RDD
- take() returns the first n elements of the RDD
- collect() returns all the elements in the RDD
- saveAsTextFile() writes the RDD to a file
Dataset:[5, 12, -4 , 7, 20]
rdd.first()
# output 5
rdd.take(3)
# output [5, 12, -4]
rdd.saveAsTextFile(“myfile”)
Note on Functional Programming
Spark uses functional programming which allows the user to process data in parallel. Functional programming is a paradigm shift from object-oriented programing and the following are some of its architectural tenants:
- Programs are built on functions instead of objects
- Mutation is forbidden – all variables are final
- Functions have input and output only – no state or side effects
- Passing functions as input to other functions
- Anonymous functions – undefined functions passed inline
Lazy Evaluation
Spark transformation operations create new RDDs from existing ones. Transformations are lazy and processing does not occur until an action is called on the RDD, or a subsequent RDD. Transformation creates a recipe, or lineage, that Spark uses to process the data. Spark will pipeline data through these transformations.
map() transformation
The map() transformation applies a function to each element of an RDD. It takes a one input to one output approach.
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.map(lambda x: x*2+1).collect()
# output --> [3, 5, 7, 9, 11]
flat_map() transformation
flatMap() applies a function to each element of the RDD and returns a collection. The main difference between map() and flatMap() are the outputs. This transformation takes a one input to many output approach.
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd.map(lambda x: [x, x*2]).collect()
# output -> [(1,2), (2, 4), (3,6), (4,8), (5,10)]
rdd.flatMap(lambda x: [x, x*2]).collect()
# output -> [1, 2, 2, 4, 3, 6, 4, 8, 5, 10]
Key Value Pair (KVP)
Pair RDDs are a different type of RDD than previously discussed. A Pair RDD, or Key Value Pair (KVP) RDD, is an RDD whose elements comprise a pair of – key and value. Pair RDDs are very useful for many applications. We can create KVPs then allow group operations to occur based on the key. Examples of these operations include join(), groupByKey() and reduceByKey().
Word Count Program in PySpark
text_file = sc.textFile("hdfs:///….test/inputfile.txt") // text_file is an RDD and each element of the RDD is one line of the file
counts = text_file.flatMap(lambda line: line.split(" ")) \ //flatMap returns every word (separated by a space) in the line as an Array
.map(lambda word: (word, 1)) \ //map each word to a value of 1 so they can be summed
.reduceByKey(lambda a, b: a + b) // gets a dataset of the count of every unique word by aggregating all the 1's written in map step
counts.saveAsTextFile("hdfs:///test/outputfile.txt")