Apache Hive
Apache Hive is a data warehouse infrastructure built on top of Apache Hadoop that provides data summarization, ad-hoc query, and analysis of large datasets. It projects structure onto the data in Hadoop and queries that data using an SQL-like language called HiveQL (HQL).
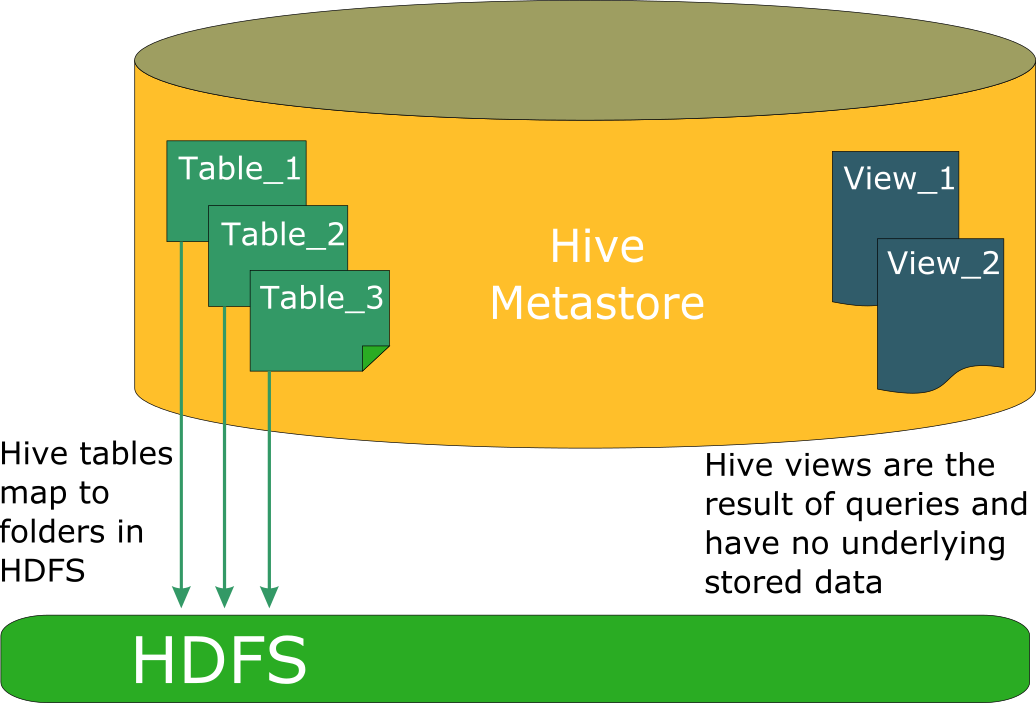
Tables in Hive are similar to tables in a relational database.Data can be accessed via a simple query language and Hive supports overwriting or appending data. Within any particular database, data in the tables is serialized and each table has a corresponding Hadoop Distributed File System (HDFS) directory.
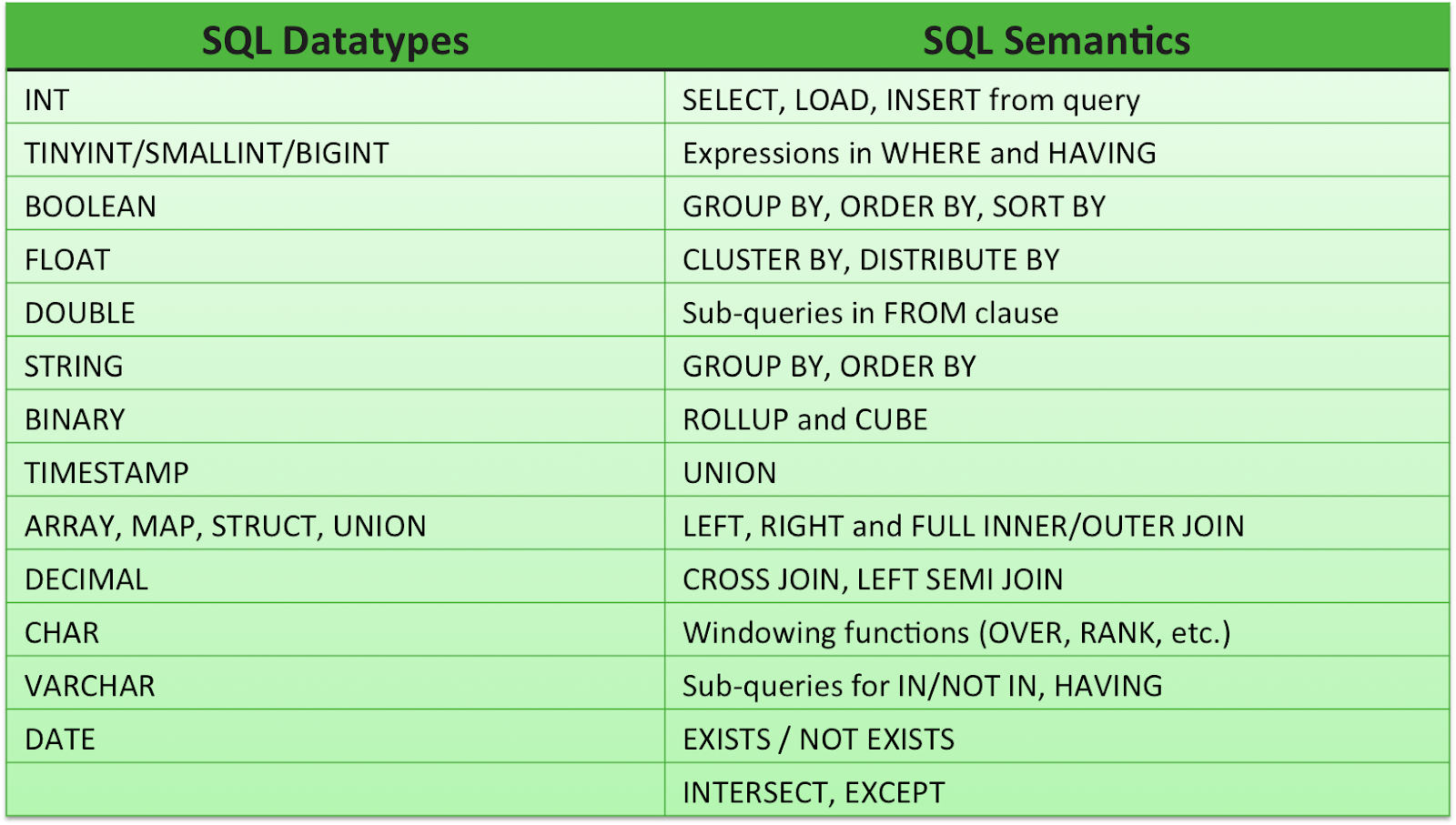
Hive supports all the common primitive data formats such as BIGINT, BINARY, BOOLEAN, CHAR, DECIMAL, DOUBLE, FLOAT, INT, SMALLINT, STRING, TIMESTAMP, and TINYINT. In addition, analysts can combine primitive data types to form complex data types, such as structs, maps and arrays.
Hive also allows programmers familiar with the MapReduce framework to plug in their custom mappers and reducers to perform more sophisticated analysis that may not be supported by the built-in capabilities of the language.
Hive users have a choice of 3 runtimes when executing SQL queries. Users can choose between Apache Hadoop MapReduce, Apache Tez or Apache Spark frameworks as their execution backend
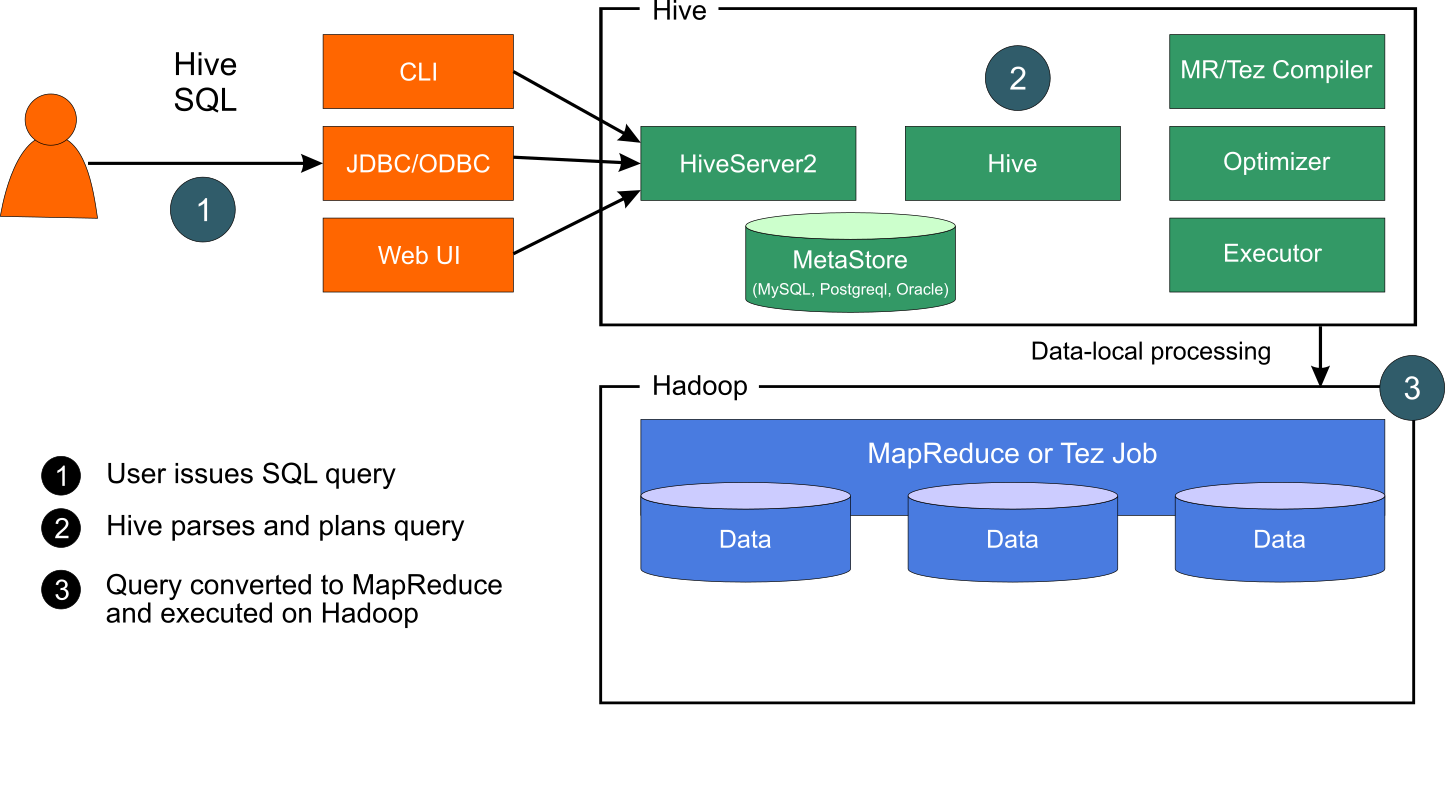
SQL in Hive
Submitting Queries
Beeline is the CLI for HiveServer2. Beeline is started with JDBC URL of the HiveServer2 GUI Tools
Ambari Hive View Zeppelin DBVisualizer SQLWorkBench
HiveServer2
HiveServer2 is built on Thrift (one of the cross-language serialization/RPC framework which support communication between variety of programming languages) Several bug fixes and concurrency and authentication issues are fixed
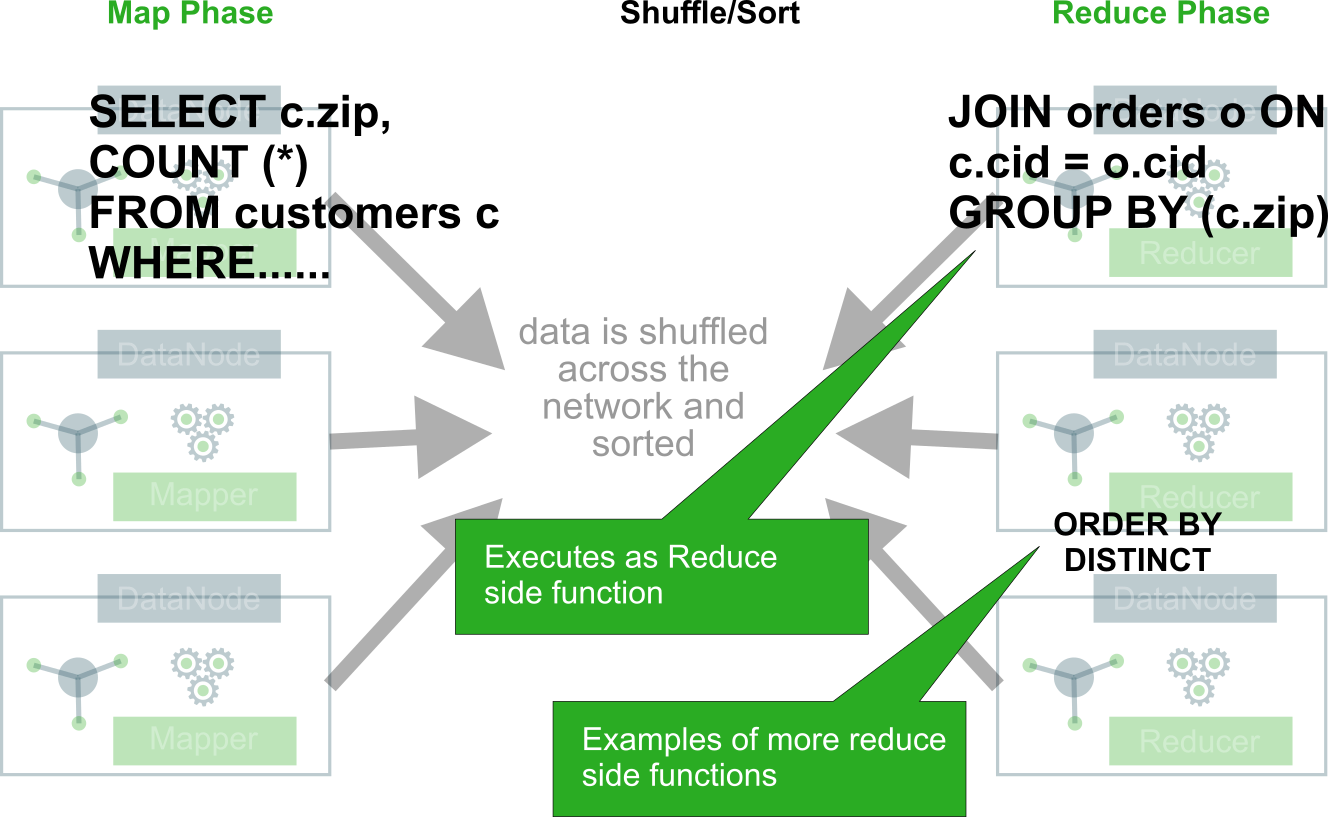
Performing Queries in Hive - MapReduce under the cover
Defining a Table

Defining External Table
An external table is a table for which Hive does not manage storage. If you drop an external table, only the definition in Hive is deleted. The data remains. An internal table is a table that Hive manages. If you drop an internal table, both the definition in Hive and the data are deleted.

Location specification

If a LOCATION is not supplied, the table’s data will reside in /apps/hive/warehouse/db_name/table_name
Loading from different file systems

Ambari Hive View
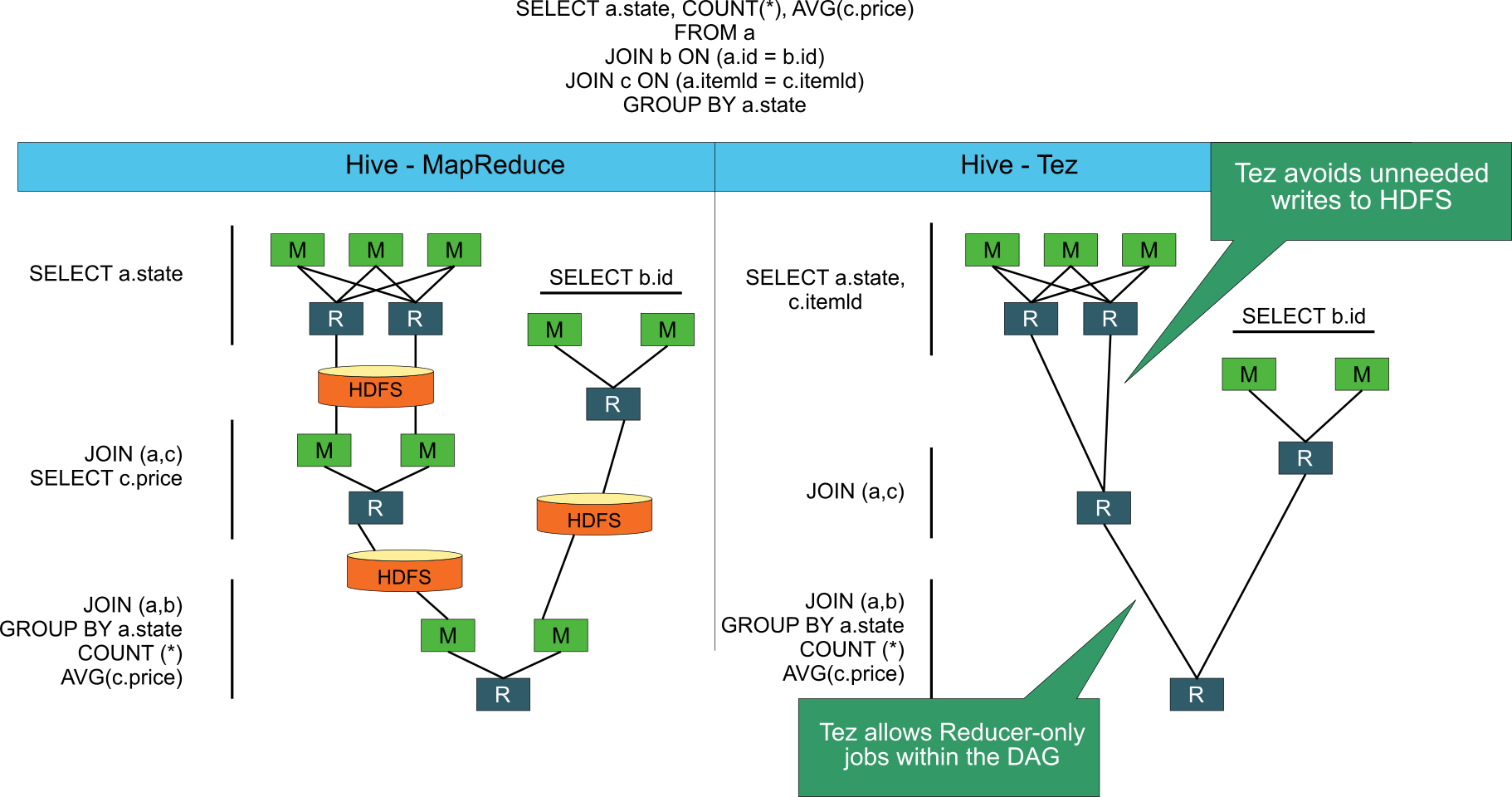
Performance Improvements
Both Stinger and Tez have increased the performance of Hive queries.
The Stinger Initiative enables Hive to support beyond its Batch roots to support interactive queries – all with a common SQL access layer.
Tez improves the MapReduce paradigm by dramatically improving its speed, while maintaining MapReduce’s ability to scale to petabytes of data.
Hive has always been the defacto standard for SQL in Hadoop and these advances are helping production deployment of Hive across a much wider array of scenarios.
HCatalog
Apache™ HCatalog is a table management layer that exposes Hive metadata to other Hadoop applications. HCatalog’s table abstraction presents users with a relational view of data in the Hadoop Distributed File System (HDFS). It also provides REST APIs so that external systems can access these tables’ metadata. 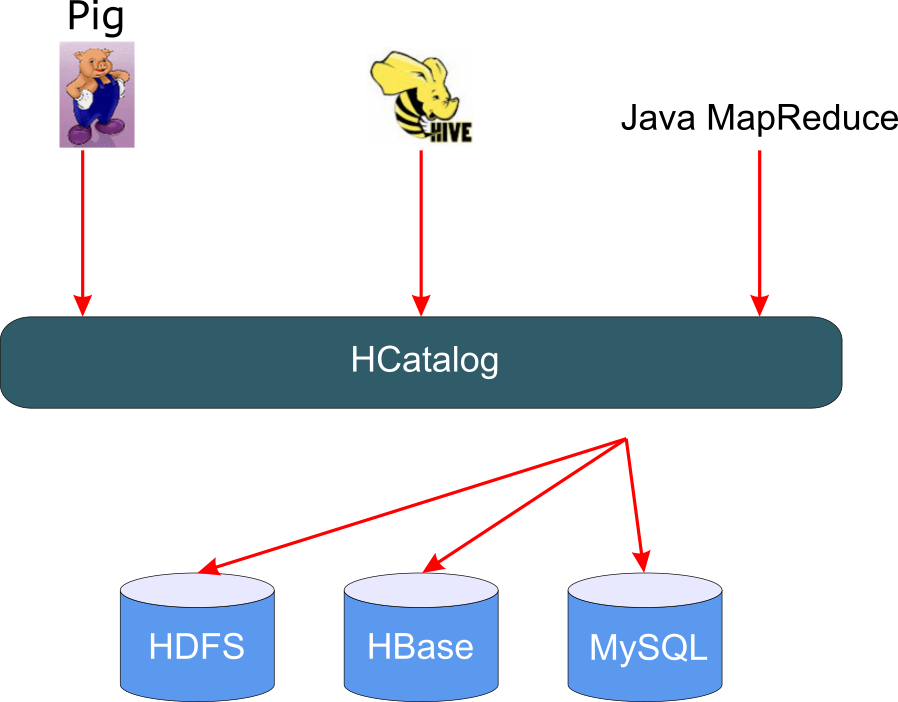
HIVE Overview
- Hive is the data warehouse system for Hadoop and uses the familiar table and SQL metaphors that are used with classic RDBMS solutions
- Hive can create, populate and query tables
- Views are supported, but are not materialized