Apache Spark
As Hadoop picked up its popularity there were many drawbacks that were noted as well and here are some of the important ones that inspired for Spark to come into existence:
- Hadoop was only supporting MapReduce use cases written in Java that was very verbose and needed a lot of boilerplate setup
- Hadoop was only supporting batch processes and there was no support for interactive processing
- Hadoop was too slow as it was reading and writing to disk in all the intermediate steps and large MR jobs took several hours or days to complete
- Hadoop was only able to process data at rest, meaning data that is stored on disk and there was no support for streaming data.
To address these above issues and beyond, Spark was created as a general purpose data processing engine and was later released as a top level Apache project, focused on fast processing of data using in-memory distributed computing.
In-Memory Processing Improvement
In Hadoop processing results from mappers, reducers were written to file system. When you submit jobs of directed acyclic graph of Map Reduce, intermediate results would be stored in HDFS. Writing to disk although has the advantage of persistence, is inefficient and takes a lot of time for both read and write in comparison to using the RAM memory of the machines. This was the first big improvement that Spark addressed. 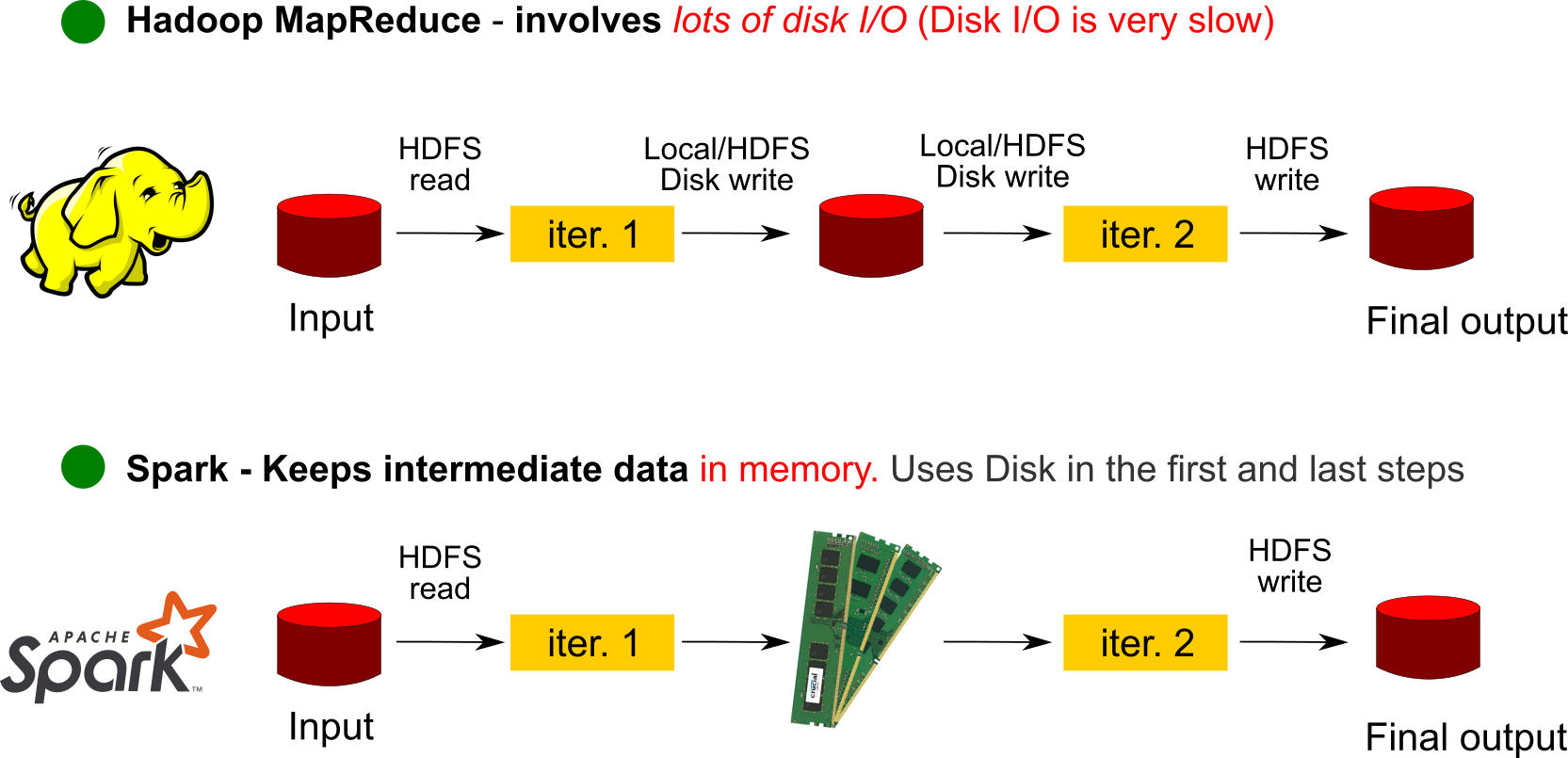
Processing Improvements
Spark took many concepts from MapReduce and implemented them in new ways to improve efficiency. Spark builds its query computations as a directed acyclic graph (DAG) and uses its query optimizer decomposes into tasks that are executed in parallel in the cluster. It also has a code execution engine, Tungsten, that generates compact code that is optimized for modern compilers and CPU's for execution.
Spark core applications were written in Scala, and could be used by either Scala or Java. But today, you can use many programming languages including, Python and R to write your Spark programs. The core Spark API's still focus on using key/value pairs for data manipulation. However, the API is simplified for usage.

As can be seen in the example picture above, in certain use cases there is a 100 times improvement in speed of execution and the program itself in Spark is very simple to write and implement.
Module Support
In addition to the core Spark API, a few wrapper frameworks have been developed on top of the core API. Most notable is the Spark SQL module. The Spark SQL module allows developers to seamlessly mix SQL queries within their Spark applications. It also provides additional module for machine learning algorithms MLlib, streaming data support GraphX library support for manipulating graphs that can be used to analyze social network graphs, network topology etc.) and performs graph-parallel computing by providing standard graph algorithms for analysis by applying algorithms such as PageRank, Connected Components, and Triangle Counting, etc.

Multiple Datasource Support
Hadoop provided solution for both storage through HDFS and processing through Map Reduce. Spark focused on processing and gave support to get data from not only HDFS but from any of the popular data sources like RDBMS, NoSQL databases like MongoDB, Cassandra, search engines like Solr, Elastic Search, streaming data from Kafka etc..
Spark Basic Building Blocks
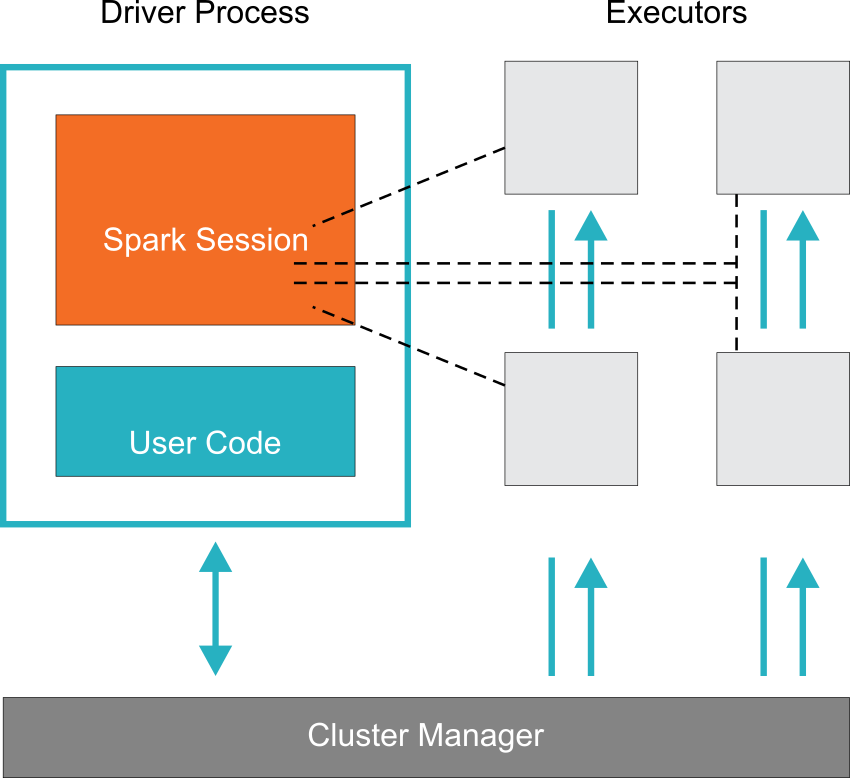
Spark Architecture consists of the following main components:
- Driver program - responsible for orchestrating parallel computing in the cluster using Spark Session
- Spark Session - Driver program spawns a Spark session through which the distributed computing gets started
- Spark Executor - This is the program responsible for running the broken down tasks in the cluster. Mostly it spawns one executor program per node.
Spark Driver Program
This component is the main brain for distributed computing paradigm. It communicates with the cluster manager to request resources (CPU, memory etc.) and it transforms all Spark programs into a DAG (Directed Acyclic Graph) computation, schedules them to be executed in the Spark executors
Spark Session
Provides entry point for parallel computing environment. With Spark 2.0, this is the only object necessary for starting parallel execution for any of the modules or datasources and thus making it simpler to use Spark on any of the components
Before this, you had to open SparkContext for Spark API, for SQL you had to start a SQLContext, for Hive you had get a HiveContext, StreamingContext for streaming data etc., to keep backward compatibility, you can still get these contexts from the Spark Context but is no longer necessary for its usage. Just opening a SparkSession will do.
Cluster Manager
This component is responsible for managing and allocating resources for the cluster. Spark comes with a built in cluster manager. You can also configure to use YARN, Mesos or Kubernetes
Spark Executor
This component runs on each worker node in the cluster. Executors communicate with the driver program and are responsible for executing distributed tasks on the workers. In most deployments one executor runs on one node but this can be changed through configuration settings.
Data Partitioning
Data is read into Memory and then partitioned to allow for efficient parallelism. Spark executors process data that is close to them to save network bandwidth. Each executor is assigned its own partition to work with.
SPARK Advantages
- Speed - through in memory processing, processing improvements
- Ease of use - high level API, DataFrame support, multiple programming language (Java, Scale, Python and R) support
- Modularity - core spark, spark SQL, streaming module, MLlib, GraphX
- Extensibility - can read data from HDFS, Cassandra, HBase, MongoDB, RDBMS, Amazon S3, Azure Storage, Kafka etc.
- RESTful API - spark provides a RESTful API for managing jobs
- Spark Shell - sparks provides shell for interactive data exploration and manipulation; used in data discovery
- Batch support - can schedule independent programs to be run at scheduled time. Used in ETL, streaming, model building etc..
- MLlib allows data scientists the ability to easily scale machine learning algorithms
Local PySpark Installation
You can install PySpark on your local using the below command
pip install pyspark
Once installed, you can open a spark session by running the below command
pyspark
Local Spark-SQL Installation
You can install other add-ons; for example SQL support using the command below
pip install pyspark[sql]
Reference: https://spark.apache.org/docs/latest/api/python/getting_started/install.html