Hadoop
So at the heart of the Big Data challenge, we have to answer basically two questions
- How to efficiently store this massive amount of data?
- How to quickly process this massive amount of data?
In 2005, both these problems were solved with Apache Hadoop application!
What is Hadoop?
MapReduce was the processing technique, released as a research paper by Google in 2004.
Apache Hadoop (simply called Hadoop) is an application originally written by Doug Cutting and Mike Cafarella, in 2005 that implements the Map Reduce paradigm. Doug Cutting was working in Yahoo at that time and named this application after his son's toy Elephant.
This application was written in Java and could be used by Java Developers initially. The Mapper and Reducer programs were pure Java classes. It became an instant hit with certain type of application processing as Hadoop could scale with commodity hardware; meaning you can have a Big Data system setup to process massive amount of data by using cheap computers from Best Buy! All types and configurations of computers could be used to build a Hadoop Cluster. This was a game changer as till then any powerful system needed a powerful computer like mainframe, super computers etc.. But here was a system that could run on any small to big computer and all of them when installed with Hadoop software and configured to work as one cluster, could help in distributed processing of data!
Hadoop provided solution for both the challenges;
- It provided HDFS for massive data storage
- It provided MapReduce framework for massive data processing
So Hadoop is an open source framework for the distributed storing and processing of large sets of data on commodity hardware. Hadoop clusters can range from as few as one machine to literally thousands of machines.
Hadoop is the first system that used commodity hardware to solve Big Data problem and also provided:
Scalability: Increasing the number of machines should result in a linear increase in processing capacity and storage.
Fault tolerance: If one of the nodes in a distributed cluster fails, the job processing shouldn’t fail and the data that is stored in the cluster is recoverable.
Hadoop = Storage + Compute
Today, the latest Hadoop version 3.x.x provides all the above plus many performance improvements to the earlier version, along with changes in architecture to improve efficiency like support for 3 name nodes for e.g., YARN's opportunistic containers and distributed scheduling etc..
Main modules of Hadoop are:
- Hadoop Common: contains libraries and utilities needed by other Hadoop modules
- Hadoop Distributed File System (HDFS): a distributed file-system that stores data on the commodity machines, providing very high aggregate storage capabilities
- Hadoop YARN: a resource-management platform responsible for managing compute resources in clusters. Think of this as the distributed operating system that manages all tasks that run on the cluster.
- Hadoop MapReduce: a MapReduce based programming API that can be used for large scale data processing using the cluster
Hadoop is designed with the fundamental assumption that hardware and/or network failures (of individual machines, or racks of machines) are common and thus should be automatically handled by the framework. Map/Reduce paradigm not only provided means for parallel processing but also was fault tolerant and incorporated data locality features. Data locality feature ensures that program is run where the data is stored, instead of moving the data to where the program is running.
Hadoop Ecosystem
Once Hadoop started gaining traction in the industry, there were many other software that were written to augment Hadoop's ease of operation and usability.
Early Hadoop could be used only by the Java Developers. But since there were a lot of analysts who frequently use SQL to analyze data, Hive was developed, which would run MapReduce jobs in Hadoop by accepting SQL like queries. Similarly Pig was added for those who wanted to use Pig Latin scripting language for data processing.
And thus an ecosystem developed around Hadoop. New applications were written and added to the ecosystem that either made Hadoop more easy to use by different sects of people or added additional functionality to the existing API.
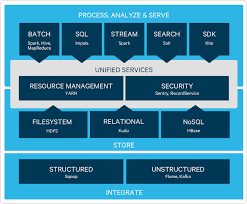
Hadoop itself has evolved over the years. You will learn more on some of these application later in the eBook.