Apache Beam
Unifies batch processing and streaming processing into one unified structure to create your own Data processing pipeline.
Apache Beam = Batch + Stream
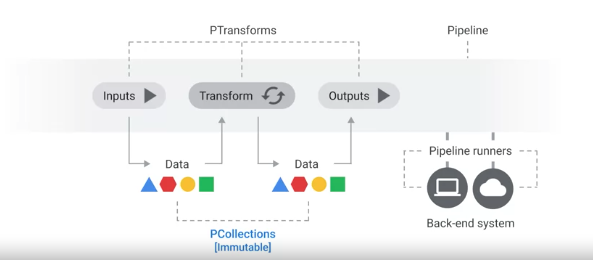
The main components are:
- PCollections - immutable distributed data structure
- PTransforms - main processing unit that receives input, transforms the input PCollection data and outputs another PCollection data to another PTransform
- Pipeline Runners - typically Kubernetes engines
- Pipeline - a Pipeline can be run on a local computer, in a Virtual Machine, in the data center, or in a service in the Cloud, such as Cloud Dataflow.