Map Reduce Paradigm
Map Reduce is the main distributed processing technique that started the Big Data revolution. Today we have many different techniques but Map Reduce still has its place.
History of Parallel Computing
Parallel computing has been the solution since many decades for faster processing of data by employing multiple processor to complete the task.
However, the scientists working on improving paralle computing were not getting their limelight because:
- Microprocessors are becoming cheaper and faster every day
- Computer power double every 18 months for the same price.
So people preferred buying and replacing with better processors instead of employing multiple old processors.
But with the advent of Big Data, parallel computing got a new lease of life in the last 10-15 years! Just one processor is not enough for computing Big Data. You indeed need parallel processors.
Understanding Efficiency in Parallel Computing
So if you have a task that takes 10 minutes with one processor then if you throw two processors to do the same task, your expectation would to reduce the time by half - so in ideal scenario it should take 5 mintues
But in reality that is not true and these are the definitions of speedup and efficiency in a parallel processing system
- Speedup time S = T1 / Tp, time with p processors vs with 1.
- Efficiency E = T1/ p Tp where p is the expected speedup for p processors.
So it so turns out that as the processors were added to a task, the efficiency kept dropping in traditional parallel processing solutions: 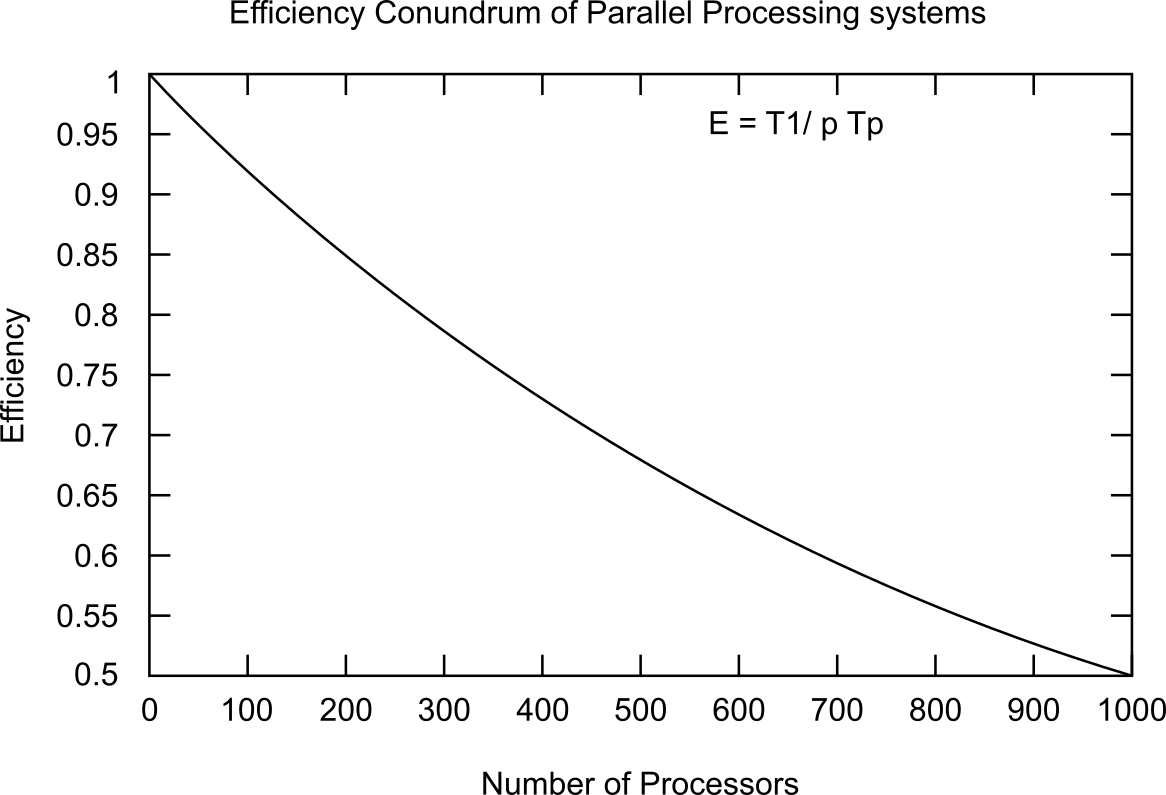
This was because for the most part the common data that was used by all processors was under lock by one processor and hence other processors were in a waiting game to get their turn to do their job! This was no good obviously.
Advent of MapReduce
Map Reduce concept of distributed processing was originally introduced by Google engineers and was made public after a while.
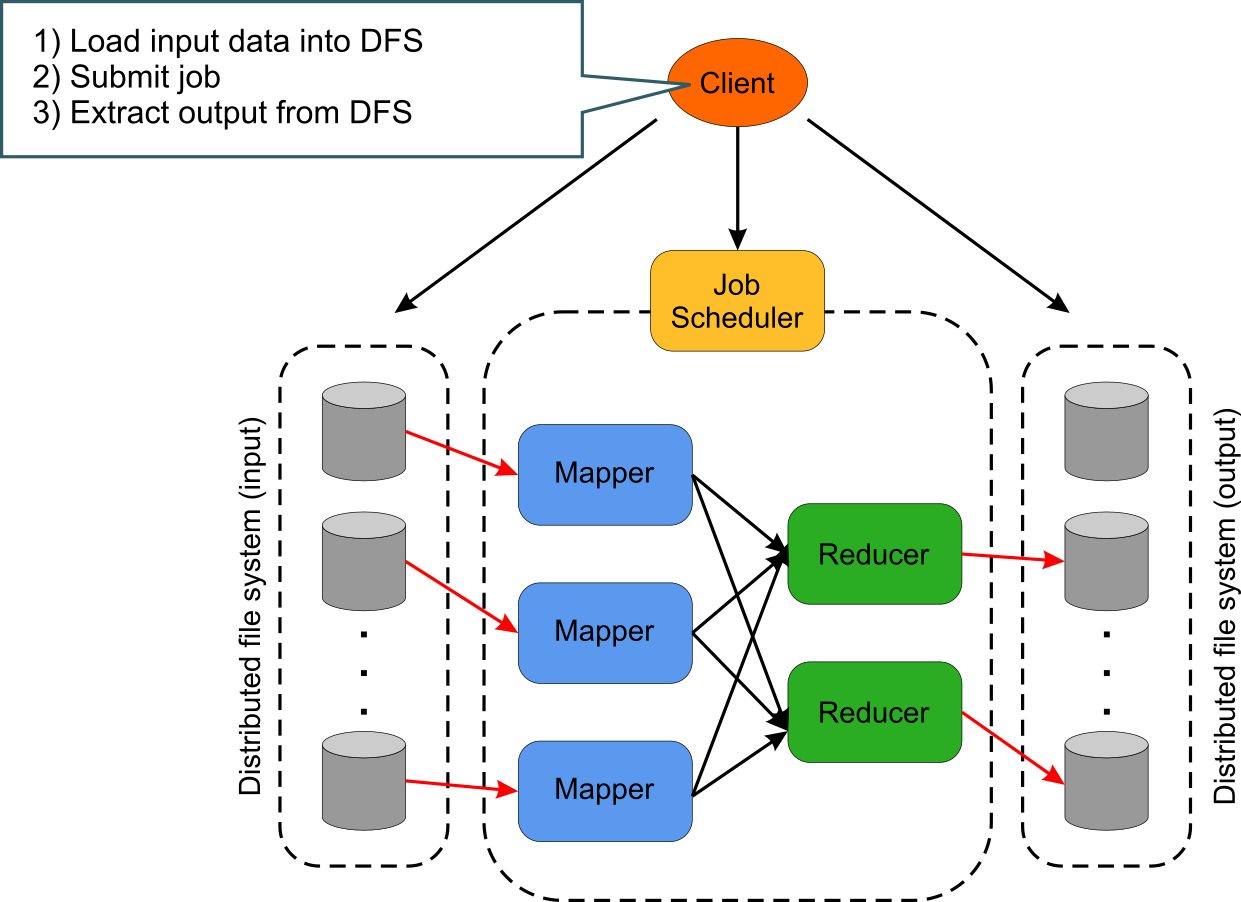
Map Reduce is a technique of processing large datasets in a distributed environment using multiple processors over several machines.
To do this you have to ask two fundamental questions;
- How can I split this problem into sub problems that can be solved independently in parallel? - you create a Mapper to handle this
- How can I combine the results from all the parallel processors to form a final result? - you create a Reducer to handle this
Technically, Mapper is mapping your data set into a collection of key,value pairs and then reducing all pairs with the same key to get your final processed output. The over all concept for your processing should line up for this paradigm.
Basically if your processing can be broken down into these two steps:
- Data can be mapped into key,value pairs somehow
- Keys and values may be of any type; string, integers, key,value pairs itself, etc.
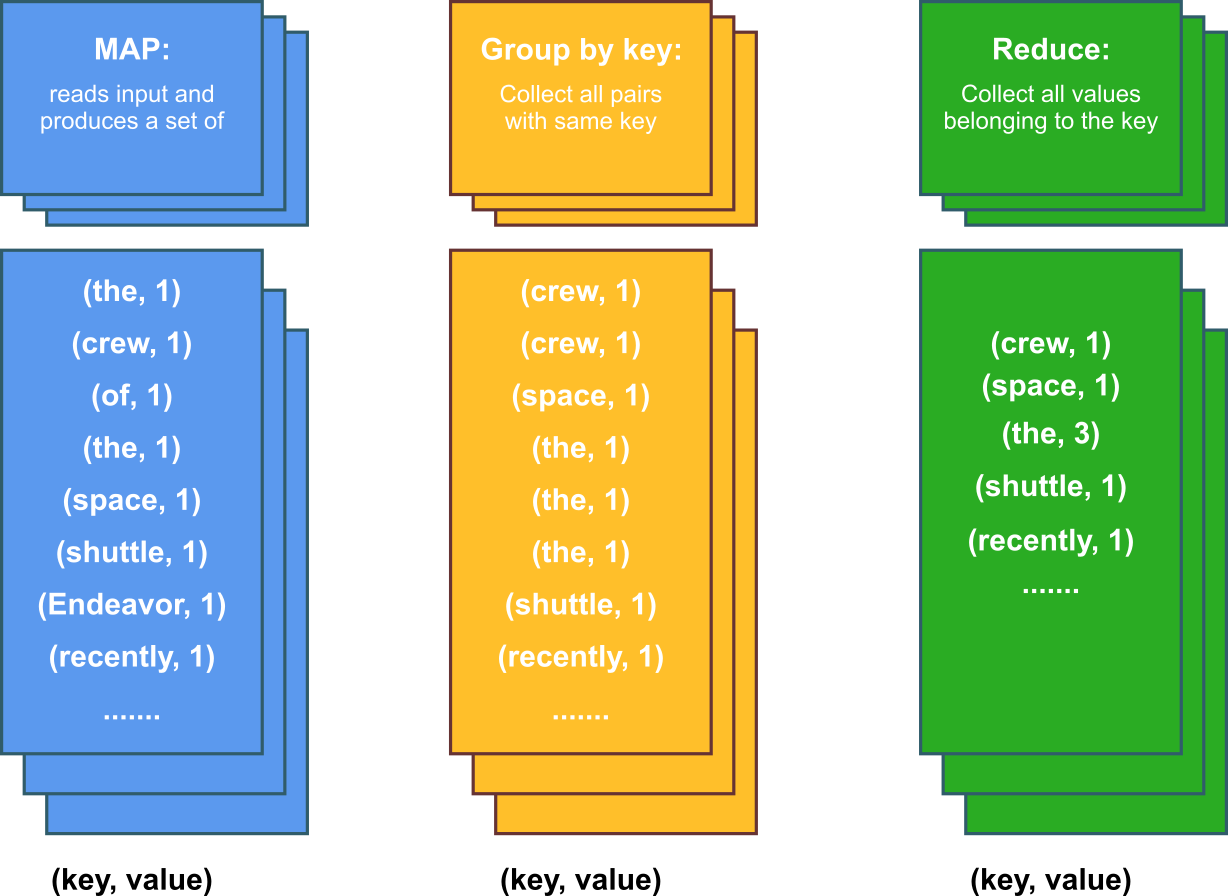
Word Count using Map Reduce
The 'helloworld' program of Hadoop is the Word Count Problem!
What is this World Count Problem?
This is a challenge to count not only the distinct words in thousands of text documents but also find the count of each word. I.e., how many times (frequency) it appears in all of the documents put together. This is a great example to use Hadoop. You would to distribute the documents across multiple nodes of a hadoop cluster to complete this job.
To accomplish this task the process can be divided into two phases:
- First identify each word in each of the documents
- Then count the identified words across all the documents
Both these phases are done by the cluster computers using the Map Reduce technique which is explained as below:
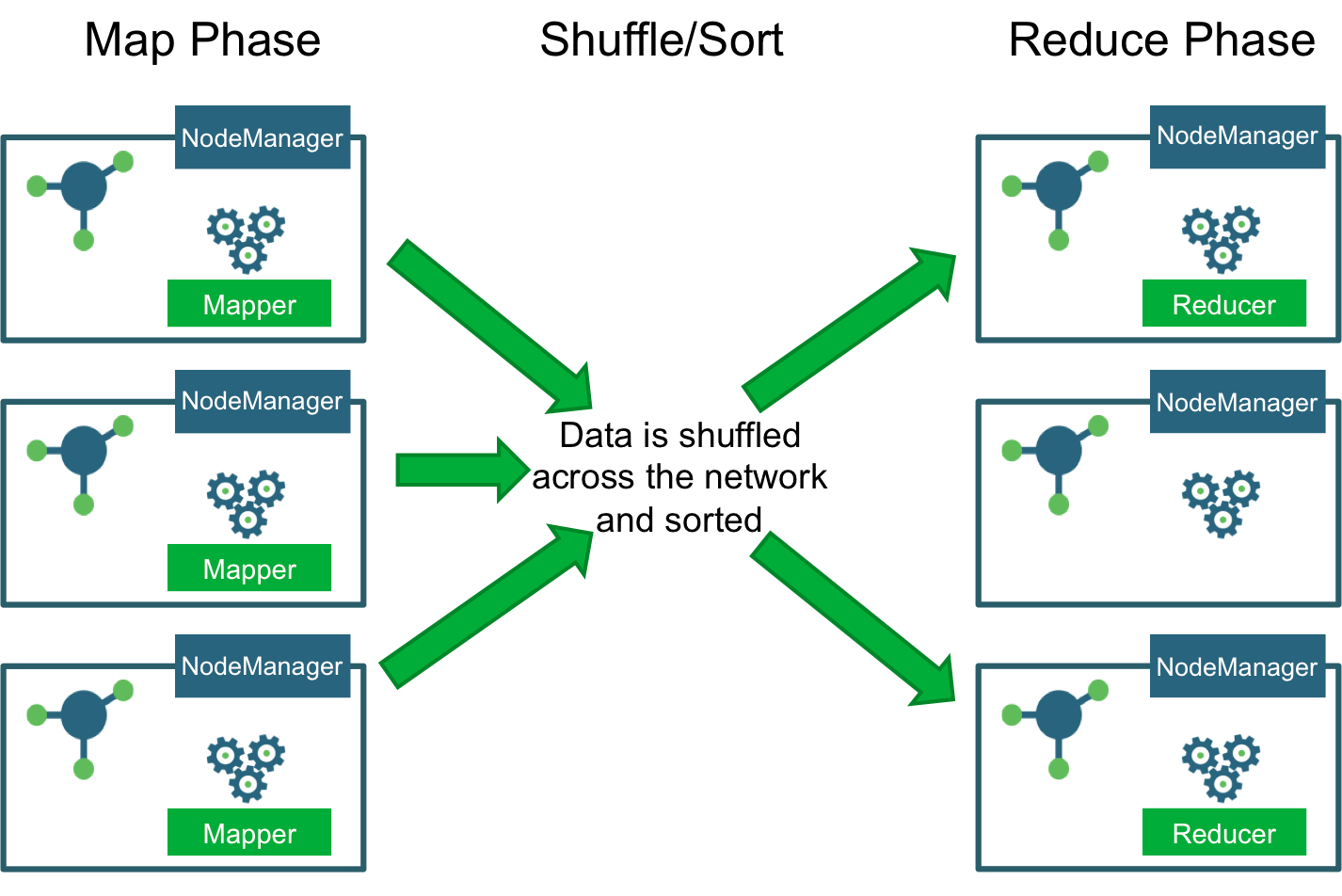
- Mapper programs are run in all nodes. Each program will get a set of documents to process. All that the mapper does is read the file, tokenize the strings, split out each individual tokens with a number '1' next to it. The result of mapper output is in a file saved in the local file system of the Mapper program
- Shuffle and Sort algorithm of Hadoop takes the output of all the mappers and keeps the sorted words ready. This sorted output will be fed to the reducer program
- Reducer programs are run in all nodes. Reducer program starts after the shuffle and sort step is done. Reducer program aggregates all the output values and finds the final count of the distinct words across all the documents.
Here is the pseudo code that shows the mapper and reducer programs
map(String key, String value):
// key: document name
// value: document contents
for each word w in value: EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values: result += ParseInt(v);
Emit(AsString(key, result));
Generic Solution Steps
While the specific word count that we learnt above is one simple example of using Map Reduce technique to accomplish our task of counting words. You can apply this technique to any problem that can be broken down into a mapper and reducer step
In general here are the steps you as programmer would take:
- Map phase - You write a custom Mapper class to handle the map phase. Data is input into the mapper, where it is transformed and prepared for the reducer
- Reduce phase - You write a custom Reducer program to handle the reduce phase. Picks the data from the mapper and performs the desired computations or analyses
Note: The shuffle/sort phase of MapReduce is a part of the framework, so it does not require any programming on your part.
Data Flow Steps
- As mappers finish their tasks, the reducers start fetching the records and storing them into a buffer in their JVM’s memory
- If the buffer fills, it is spilled to disk.
- Once all mappers complete and the reducer has fetched all its relevant input, all spill records are merged and sorted (along with any records still in the buffer)
- The reduce method is invoked on the reducer for each key
- The output of the reducer is written to HDFS (or wherever the output was configured to be sent)
Running Word Count Program
Word count program comes as an example with Hadoop installation. So if you have a requirement to count words across text documents you can simply use this program instead of creating your own Mappers and Reducers.
And here are steps to run the same on DataProc on Google Cloud:
- SSH into the Dataproc box and upload a file - e.g., test.txt into Dataproc home directory with the text for which you want to find the word count.
- Copy over the file into hdfs with the below command.
- hdfs dfs -put test.txt /
- this copies over the newly created file into hdfs / folder
- Run the below command to run wordcount example problem
- yarn jar /usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar wordcount /text.txt /tmp/output
- Map reduce job runs and the output is in /tmp/output folder of the hdfs dfs
- Copy over the hdfs output file into local with the below command
- hdfs dfs -get /tmp/output*
Points to note
- The map and reduce tasks run in their own JVM on the DataNodes
- The mapper inputs key/value pairs from HDFS files and outputs intermediate key/value pairs. The data types of the input and output pairs can be different
- After all of the mappers finish executing, the intermediate key/value pairs go through a shuffle-and-sort phase where all of the values that share a key are combined and sent to the same reducer
- The reducer inputs the intermediate
pairs and outputs its own pairs, which are typically written to HDFS - The number of mappers is determined by the input format - in simple terms the data block size
- The number of reducers is determined by the MapReduce job configuration - you can choose this setting
- The output of a reducer is typically one file per reducer in HDFS. For example, if you have five reducers, the output will be five different files