HDFS Hadoop Distributed File System
HDFS provided the means for storing massive amount of data on commodity hardware in Hadoop. HDFS is one of the two main architectural pillars of Hadoop.
So what is HDFS?
- HDFS is a Java-based distributed file system that provides scalable and reliable data storage, and it was designed to span large clusters of commodity servers.
- HDFS has demonstrated production scalability of up to 200 PB of storage and a single cluster of 4500 servers, supporting close to a billion files and blocks
- HDFS is a scalable, fault-tolerant, distributed storage system that works closely with a wide variety of concurrent data access applications, coordinated by YARN
So how does it really save huge files?
It simply divides the big files into number of small blocks (default size 128 MB, can be changed) and distributes the pieces across the cluster. It also stores multiple replicas of each block for reliability.
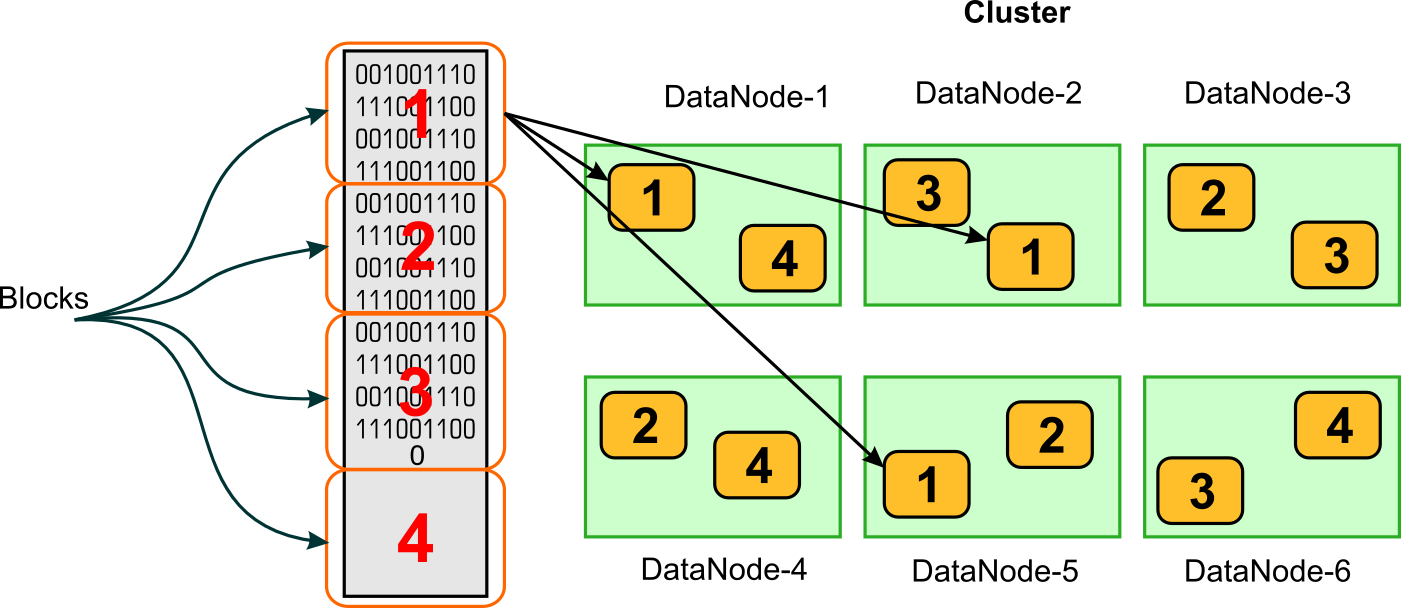
HDFS has two main components to help it execute its responsibilities:
- Name Node - The NameNode is the master service of HDFS. It determines and maintains how the chunks of data are distributed across the DataNodes. Data never reside on a NameNode.
- Data Node - DataNodes store the chunks of data, and are responsible for replicating the chunks across other DataNodes. The Default block size in HDP 128MB. The default replication factor is 3.
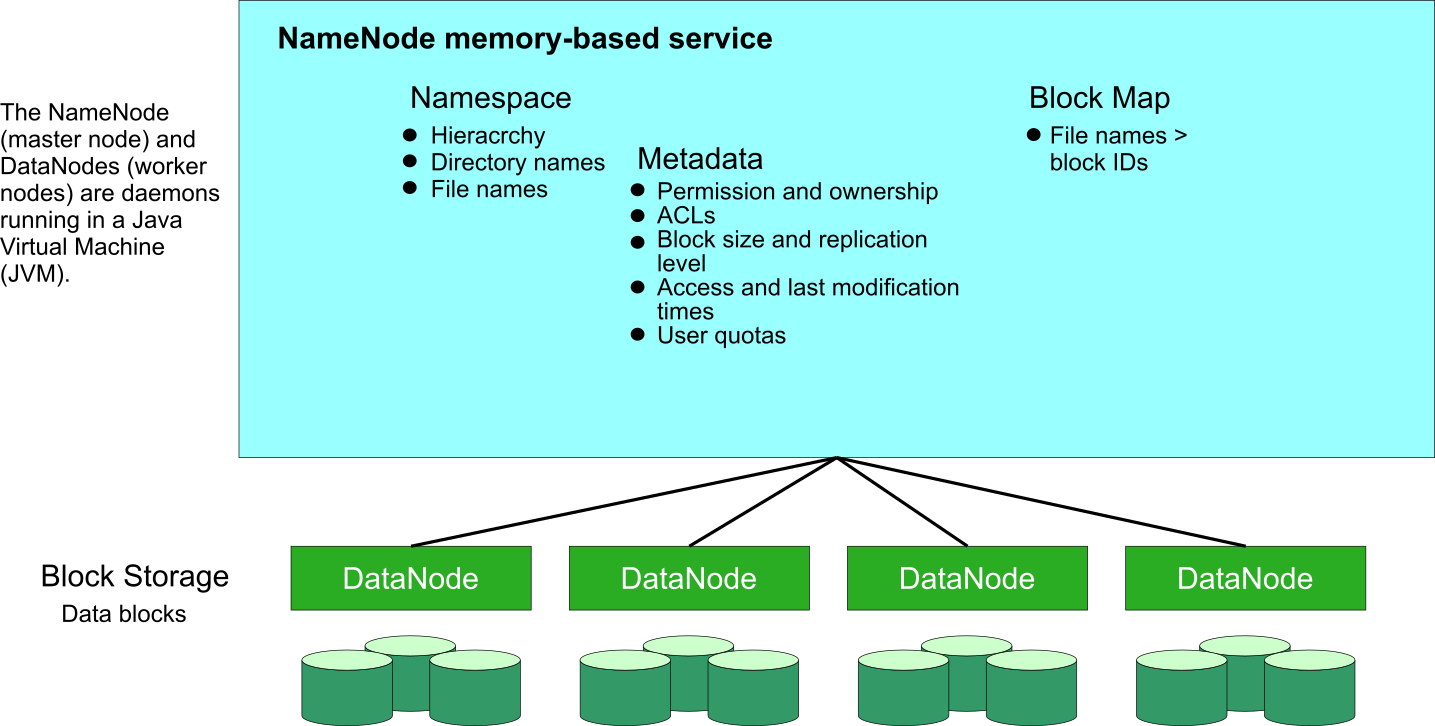
Note: The data never actually passes through the NameNode. The client program that is uploading the data into HDFS performs I/O directly with the DataNodes. The NameNode only stores the metadata of the filesystem, but is not responsible for storing or transferring the data.
Reference: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
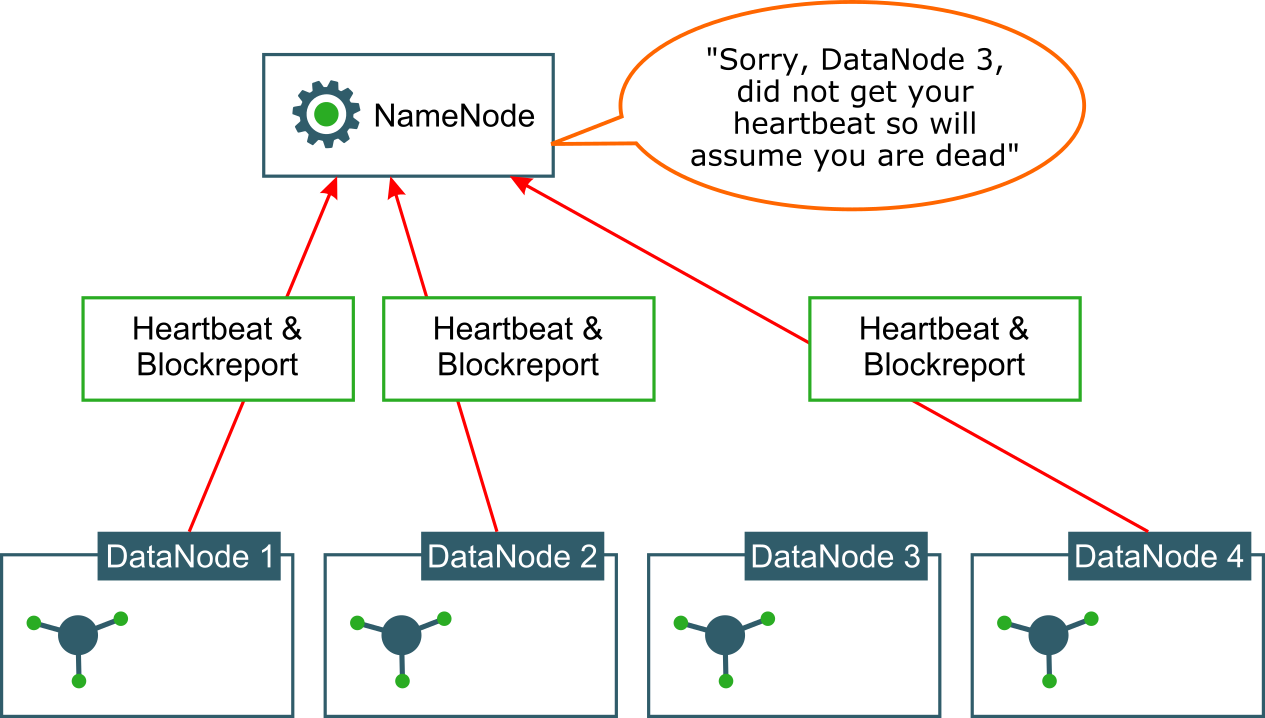
How does HDFS handle node failures?
Both the NamdeNode and DataNode components are Java processes.
When the DataNode is started (or restarted), it registers with the NameNode to let it know that it is ready for work.
All DataNodes periodically (every three seconds, by default) sends a heartbeat signal to the NameNode. This heartbeat lets the NameNode know that it is alive. If the NameNodes does not receive the heartbeat from a DataNode for extended period of time (10 minutes), it marks it as dead and then it contacts other DataNodes that have similar chunks of data to replicate the data to another DataNode that is alive and kicking. This step will bring the replication factor back to the configured number of replicas for each file block.
DataNodes also send a periodic (hourly) report to the NameNode on its data blocks as well. This report will piggyback on the heartbeat signal.
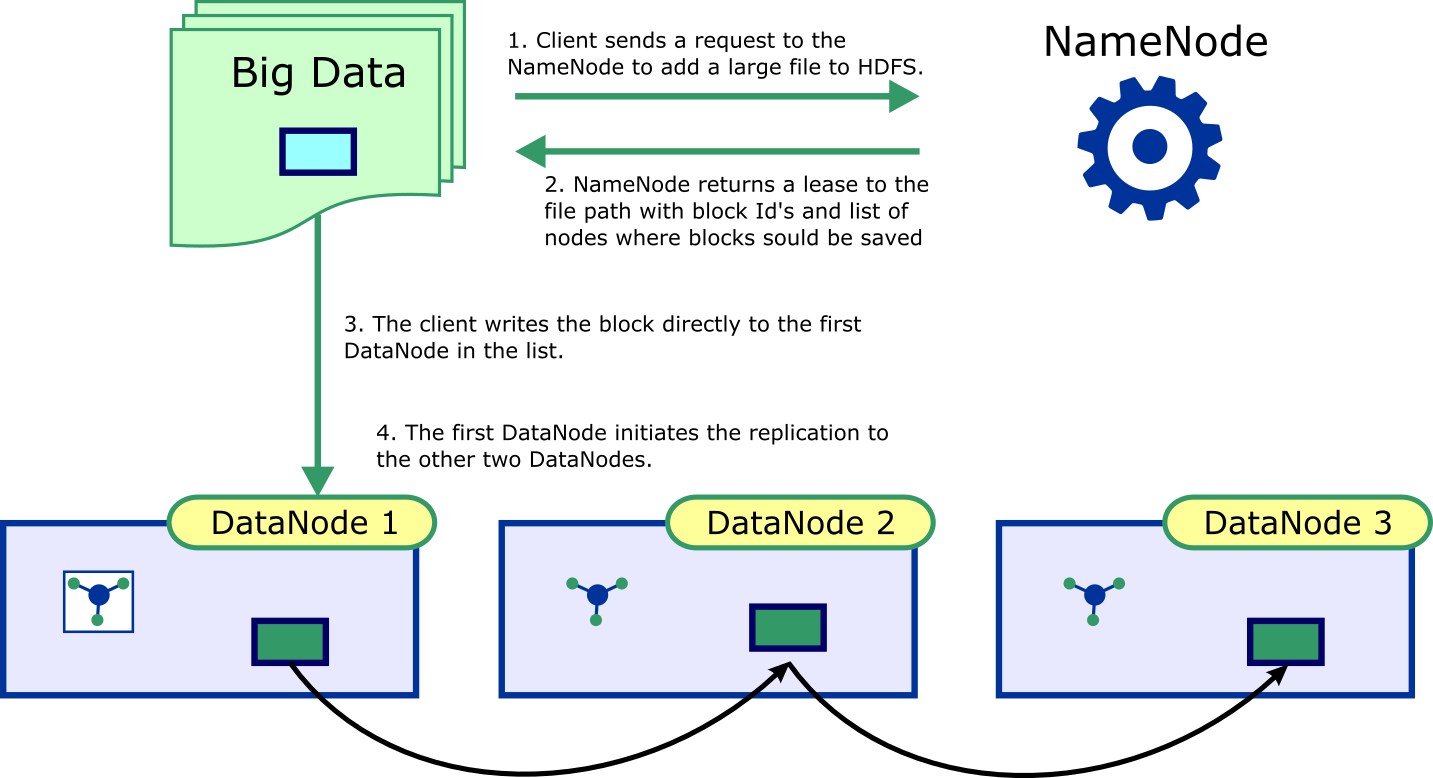
How do the Clients Read Data?
The whole purpose of storing data is to eventually read the data for all kinds of processing. Here client could be any job that tries to process the data.
The following are the steps that the clients take to read data stored in HDFS
- Make a request to NameNode for the file
- NameNode returns the addresses of the DataNodes to fetch the first few blocks of the given file, ranking the DataNodes in the order of their closeness to the client. The data could even be in the same or next node as the client. In which case that DataNode would be listed first.
- Clients reads the file in the given order. If there is a failure while reading, it reaches out to the replica next in the list
When the clients starts reading the first few blocks, a request is made to send information of the next few blocks and the cycle repeats
Points to note
- Distributed file system is ideal for WORM (Write Once Read Many times) applications
- HDFS is part of Hadoop. So to use HDFS you have to download Hadoop
- Amazon S3, Google's Storage are also distributed file systems, similar to HDFS and many big data platforms use these alternatives instead for data storage. There by you can store data without the need to having Hadoop and use Hadoop only for computing. This architecture saves you money when running in cloud.
Improvements in Hadoop 3
The latest Hadoop has several improvements over the earlier versions and here are some highlights:
Erasure Coding (EC) introduced for HDFS file storage:
Replication factor of 3, comes with a cost of 200% overhead in storage space and other resources (e.g., network bandwidth). However, for sparingly used datasets, additional block replicas are rarely accessed during normal operations, but still consume the same amount of resources as the first replica.
EC works by splitting the file, into multiple fragments (data blocks) and then creating additional fragments (parity blocks) that can be used for data recovery. EC makes it possible to recover lost or corrupted data without using replication but by reconstructing the data using parity fragments.
For e.g., in a simple 2+1 configuration, a data unit is split into two fragments, and one parity fragment is added for protection. If for e.g., the first data fragment is available but the second data fragment isn't, or vice versa, data is reconstructed from the first data fragment and the parity fragment to get the lost data in the second fragment. In typical Erasure Coding (EC) setups, the storage overhead is no more than 50%.
To apply EC, data is labelled as 'hot'(frequently accessed everyday or recently added), 'warm' (accessed only a few times a week) or 'cold' (accessed only few times a month and is at least 1 month old) based on its usage pattern. Hot data uses regular replication, warm data is stored with 1 replica in active disk tier and 1 replica in archive tier. Cold data is stored with EC. Even though the labels are applied automatically, an admin can run commands to change the labels for certain files.
More Name Nodes: To improve fault tolerance on the Name Node which turns out to be a bottle neck under heavy work loads, multiple node nodes can be spawned.
Connection to Azure Datalake: Instead of using HDFS, you can connect to other Data lakes like Microsoft Azure Data Lake and more are anticipated in this space.
HDFS DFS Commands
When you as a user want to interact with HDFS, you have many options:
- Through command line (terminal) using Linux/Unix like file system commands - most powerful and most popular among developers
- Through WebHDFS - instead of using terminal you can use a RESTful api provided for command line interface. This interface is ideal for using HDFS over HTTP using curl.
- Through Web Browser interface (Ambari, Hue's file browser) - all commands may not be available through this but it is easy to use by anyone including non developers
We will look into command line interface commands in this eBook. For command line interface you start your command with `hdfs dfs' followed by Linux looking file system commands 
Reference: http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/FileSystemShell.html
Concerted effort has been made to move from 'hadoop fs' to 'hdfs dfs'.
| HDFS Command | Linux Equivalent | Description |
|---|---|---|
| hdfs dfs -ls / | ls / | list of files in the root directory |
| hdfs dfs -mkdir /test | mkdir /test | create a directory called 'test' in the root folder |
| hdfs dfs -put testfile.txt /test/. | n/a | copy the file named testfile.txt from local file system to /test folder of hdfs |
| hdfs dfs -cp /test/testfile.txt /test/test2.txt | cp /test/testfile.txt test2.txt | Copies the file named testfile.txt to test2.txt in the /test folder |
| hdfs dfs -rm -R /test | rm -R /test | delete the folder 'test' from root with all its content |
| hdfs dfs -du -h /test | ls -R /test | list all the directories and files in the target folder. -h option also displays the file size in readable format |
| hdfs dfs -cat /test.txt | cat /test.txt | get data to display on standard output |
dfsadmin commands
dfsadmin (distributed file system administration) command is used for file system administration activities that includes refreshing nodes, setting quotas, getting file system report, enter/leave safemode, HDFS upgrade etc.
Here are some of the commonly used dfsadmin commands. Add the given commands after keying in hdfs dfsadmin 'command'
| Command | Description |
|---|---|
| -report | obtain basic file system information that includes available disk space etc.. |
| -report -live | get report of only live nodes |
| -report -dead | get report of only dead nodes |
| -refreshNodes | Namenode refreshes its datanode hostnames from the files; dfs.hosts (adds these), dfs.hosts.exclude (excludes these) |
-allowSnapshots | HDFS Snapshots are read-only point-in-time copies of the file system saved for backup |
Other Commands
There are many other commands that can be used on hdfs and here is the full listing:
https://hadoop.apache.org/docs/r3.3.1/hadoop-project-dist/hadoop-hdfs/HDFSCommands.html
Difference between local file system and HDFS
Local file system refers to the filesystem on the computer on which you are running the commands. When you copy a file into the local file system, it stays on your computer only
However when you run HDFS file system commands on your computer, you really do not know where the file got copied. Some file blocks may be copied in your computer but you really do not know which physical computer HDFS will decide to copy the file to.
HDFS File Permissions
HDFS implements a permissions model for files and directories that shares much of the POSIX model:
- Each file and directory is associated with an owner and a group
- The file or directory has separate permissions for the user that is the owner, for other users that are members of the group, and for all other users
- For files, the r permission is required to read the file and the w permission is required to write or append to the file
- For directories, the r permission is required to list the contents of the directory, the w permission is required to create or delete files or directories, and the x permission is required to access a child of the directory